1. 서비스 오픈 대비하여 Auto Scaling 켜기
팀에서 담당하는 서비스 오픈이 임박하게 되었고, 가용성 확보를 위해 ECS에 Auto Scaling을 적용해야 했다. 백엔드 팀 내에는 인프라 작업 경험자가 없었고 주니어 입장에서 서비스를 이해하는데 도움될 것으로 판단하여 자원하였다.
요청된 작업은 기존에 작성된 IaC를 수정해서 Auto Scaling을 적용하는 것이었다. 개인적으로 인프라 자체도 익숙하지 않았지만, IaC를 먼저 학습하고 적용하는 과정이 이 작업의 가장 큰 병목점이라고 생각했다. 하지만 적용하는 과정에서 해야 했던 고민들과 경험들은 단순하지 않았기 때문에 정리해서 공유한다.
2. Auto Scaling 기준값(target value)은 어떻게 판단할까?
프로덕션 서버는 몇 개월 운용되었지만 오픈되지 않았기 때문에 의미있는 트래픽을 받아본 적이 없었다. 따라서 프로덕션임에도 불구하고 서버 스펙은 낮게(0.5 vCPU, 2GB) 유지해왔다.
서버 스펙이나 Auto Scaling이 적용되는 기준에 대해 먼저 레퍼런스를 조사했다. 안타깝게도 AWS, GCP 공식문서에서는 트래픽에 따른 서버 스펙의 분명한 기준점을 제시하지 않았다.
GCP에서는 “애플리케이션을 새 VM에서 초기화하는 데 시간이 오래 걸리는 경우 대상 CPU 사용률을 85% 이상으로 설정하지 않는 것이 좋습니다.“를 확인할 수 있었다1. AWS 공식 문서에는 “리소스 비용을 효율적으로 사용하기 위해 목표값을 최대한 높게 잡되, 예상하지 못한 트래픽 상승을 위한 버퍼를 고려하라.“고 안내하고 있었다2. 사실상 두 레퍼런스는 명확한 기준을 제시하지 않고 결국 서비스 특성을 고려해서 직접 판단해야한다. 하지만 한 가지 중요한 힌트를 얻었는데, 예상하지 못한 트래픽 상승에 대한 버퍼를 고려해야한다는 점이다.
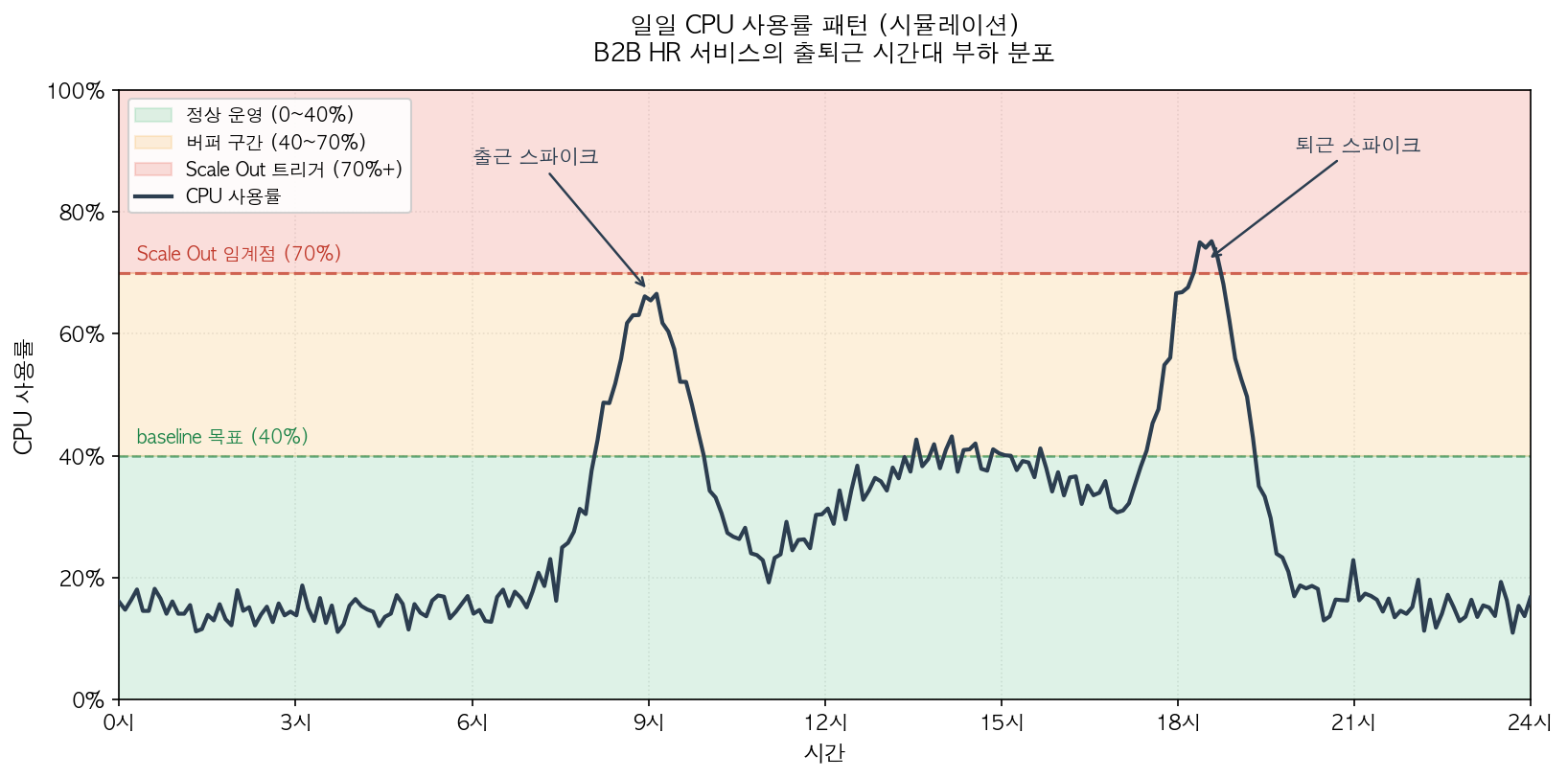
B2B HR 서비스 특성상 출퇴근 시간대에 트래픽 스파이크가 발생하기 때문에 근태 데이터의 신뢰성이 중요하다고 생각했다. 8시간을 딱 맞추고 퇴근하고 싶은데 아침에 서비스가 느려서 원하는 시간 보다 몇 분 늦게 타각된다면 사용자 입장에서는 충분히 민감하게 받아들일 수 있다.
전체 서비스 아키텍처는 MSA로 구성되어 일부 서비스는 이미 HR의 일부 분야에서는 성공적으로 운용 중이었다. 해당 서버의 메트릭(Metric)과 목표값(Target value)을 참고했을 때 CPU와 RAM Usage의 70%에서 scale out됨을 파악할 수 있었다. 다만 해당 서비스는 다른 기술 스택 기반의 백엔드 서버를 운용 중이기 때문에 지금 서비스의 자바 스프링 백엔드와의 운영환경에서 차이점은 분명 존재할 것이다.
그럼에도 적절한 시작포인트가 필요했기 때문에 동일하게 CPU, RAM Usage의 70%에서 scale out 되도록 했다. 또한, 안정성을 위해 0.5 vCPU에서 1 vCPU로 스펙업을 했고 최소/최대 태스크 수도 기존 서비스와 동일하게 min 4 / max 8로 설정했다. HR 서비스 신뢰성 측면에서 30~40% 정도의 usage가 나오도록 했을 때 이 두 배에 해당되는 70%에서 scale out되도록 한다면 출퇴근 스파이크를 대비하는 버퍼 역할을 할 것으로 예상했다. 아래 그림에서 HR 서비스의 일반적인 트래픽 패턴과 여기서 논의한 메트릭과 목표값을 이해하기 쉽게 시각화하였다.

초기값은 이렇게 정하고 서비스 안정화가 이뤄지고 실제 유의미한 트래픽이 생겼을 때 서버 스펙을 조절해서 운용 usage가 30~40이 나오도록 맞추면 될 것이다. 이런 방식으로 Auto Scaling은 트래픽이 많이 발생하는 9시 - 18시 사이에는 scale out되고 주말을 포함한 저녁과 새벽 시간대에는 자동으로 scale in되어서 불필요한 인스턴스 유지 비용을 절감할 수 있을 것이다.
3. JMeter로 부하 테스트 - Auto Scaling 동작 검증
섹션 1에서 언급했듯이 IaC 학습이 병목이라고 생각했지만 Auto Scaling을 설정하고 나니 자연스럽게 “이걸 어떻게 증명할건데?” 와 같은 질문을 하게 되었다. 따라서 JMeter3로 서버에 부하를 걸어서 언제, 어떻게 scale out, scale in 하는지 확인하기로 했다.
실험 환경
- 클러스터: 테스트 클러스터
- 대상 API: 단순 조회 API
- 스펙: 1 vCPU / 2GB Memory (프로덕션과 동일하게 맞춤)
- 부하 도구: JMeter
테스트용 클러스터가 있었고 다른 환경(스테이징, 덤프 등)은 이미 다른 팀에서 사용 중이라 제외했다. 부하 종류와 상관없이 결국 Auto Scaling이 부하에 맞춰서 동작하는지 체크하는게 목적이었기 때문에 단순한 API를 선택해서 로컬에서 AWS 클라우드에 있는 서버로 부하를 발생시켰다. 이해를 위해 전체 아키텍처와 트래픽에 따른 서버 부하 상태를 구별하여 아래 그림으로 표현했다.
flowchart LR
JMeter["🖥️ JMeter<br/>(부하 생성)"]
subgraph AWS
ALB["ALB<br/>(로드밸런서)"]
subgraph ECS["ECS Cluster"]
Task1["Task 1<br/>Spring Boot<br/>1 vCPU / 2GB"]
Task2["Task 2<br/>Spring Boot<br/>(scale out 시 생성)"]
end
CW["CloudWatch<br/>CPU/RAM 알람"]
ASG["Auto Scaling<br/>min 4 / max 8<br/>target: CPU 70%"]
RDS["RDS<br/>(MySQL)"]
end
JMeter -->|HTTP| ALB
ALB --> Task1
ALB -.-> Task2
Task1 --> RDS
Task2 -.-> RDS
CW -->|"CPU > 70%"| ASG
ASG -->|scale out| Task2
style JMeter fill:#e74c3c,stroke:#c0392b,color:#fff
style Task1 fill:#e74c3c,stroke:#c0392b,color:#fff
style Task2 fill:#27ae60,stroke:#1e8449,color:#fff,stroke-dasharray: 5 5
Thread 수를 단계적으로 올리며 CPU 관찰
JMeter와 부하테스트는 생소했기 때문에 테스트 자동화를 하지 않고 최대한 단순하게 목적에 집중했다. 대신 스레드 수를 1에서 80까지 단계적으로 올렸고, 각 단계에서 CPU 부하가 평평해질 때까지 기다렸다가 안정화가 되면 다음 단계로 넘어가는 수동 방식으로 진행했다.
당시 부하테스트 방법과 절차에 대한 경험이 없었지만 기계재료공학 연구원으로 있을 때는 숱하게 인장 실험 같은 부하테스트를 했었기 때문에 이 방식이 당연하다고 여겼다.
각 스레드는 요청을 보내고 응답을 받으면 1초 대기(Timer) 후에 다시 요청하도록 했다. 아래 테이블에 스레드 수에 따른 CPU, Memory 사용률을 정리했다.
| Threads | Ramp-up | Loop | Timer | CPU (%) | Memory (%) |
|---|---|---|---|---|---|
| 1 | 1s | infinite | 1000ms | 3 | 29.7 |
| 5 | 1s | infinite | 1000ms | 9.76 | 29.87 |
| 20 | 1s | infinite | 1000ms | 33.16 | 29.98 |
| 50 | 1s | infinite | 1000ms | 62.51 | 30.1 |
| 80 | 1s | infinite | 1000ms | 93 | 29.8 |
결과적으로 스레드 수에 따라 CPU 사용률이 높아지는 것을 확인할 수 있었다. 단계별로 올라서 결국 80개의 스레드가 동시에 요청을 보낼 때 CPU 사용률이 93%까지 높아졌다. 하지만 Memory 사용률은 영향을 받지 않았는데, 이 테스트에 CPU Bound의 단순 조회 API를 사용했기 때문에 예상된 결과였다.
4. Scale Out / In 관찰과 Grace Period 이슈
실험을 통해 scale out과 scale in을 관찰할 수 있었지만 동작 방식을 정확히 이해할 필요가 있었다. 이해하지 못하면 예상치 못한 동작으로 문제가 발생할 수 있고, 원하는 방식으로 컨트롤할 수 없기 때문이다.
특히 IaC와 콘솔로 작업하게 되면 AWS가 제공하는 추상화에 의해 많은 동작들이 가려져 있음을 이번 경험을 통해 알 수 있었다. 예를 들어, CPU Usage 70%에서 scale out하는 설정을 입력했다면 내부적으로는 CloudWatch 알람 생성, 메트릭 집계, 양방향 트리거 등 여러 메커니즘이 존재한다. 따라서, 관찰 결과를 전달하기 전에 AWS Auto Scaling이 CloudWatch와 함께 어떻게 동작하는지 정리하려고 한다.
CloudWatch 알람의 동작 원리
아래 그림은 AWS 공식 문서 “How target tracking scaling for Application Auto Scaling works”4에 있는 다이어그램을 좀더 이해하기 쉽게 재생성했다. 참고로 해당 문서의 “How it works"과 “Considerations” 섹션은 ECS 기반의 Auto Scaling을 운용 중이라면 원문으로 읽어볼 만 하다.
flowchart LR
Workload["👥 Workload<br/>증가/감소"]
subgraph Resources["인스턴스 메트릭"]
R1["📦"]
R2["📦"]
R3["📦"]
end
CW["📊 CloudWatch<br/>Alarm"]
AAS["Application Auto Scaling<br/>(내부 동작은 불투명)"]
ECS["⚙️ ECS Service<br/>(태스크 배치 + 실행)"]
subgraph Scaled["새 태스크"]
N1["📦"]
N2["📦"]
N3["📦"]
N4["📦"]
end
Workload --> R1
Workload --> R2
Workload --> R3
R1 --> CW
R2 --> CW
R3 --> CW
CW -->|"alarm 발생"| AAS
AAS -->|"desired count 변경"| ECS
ECS --> N1
ECS --> N2
ECS --> N3
ECS --> N4
style Workload fill:#fff,stroke:#333,stroke-width:2px
style R1 fill:#e74c3c,stroke:#c0392b,color:#fff
style R2 fill:#e74c3c,stroke:#c0392b,color:#fff
style R3 fill:#e74c3c,stroke:#c0392b,color:#fff
style CW fill:#fff,stroke:#ff9800,stroke-width:2px
style AAS fill:#222,stroke:#000,color:#fff,stroke-width:2px
style ECS fill:#fff,stroke:#9b59b6,stroke-width:2px
style N1 fill:#27ae60,stroke:#1e8449,color:#fff
style N2 fill:#27ae60,stroke:#1e8449,color:#fff
style N3 fill:#27ae60,stroke:#1e8449,color:#fff
style N4 fill:#27ae60,stroke:#1e8449,color:#fff
먼저 Auto Scaling을 위해 메트릭과 목표값을 CPU, RAM usage 70%로 정했다. 이 설정값으로 AWS CloudWatch는 메트릭마다 두 개의 Alarm을 생성(총 4개)한다. 하나는 scale out 목적의 AlarmHigh, 다른 하나는 scale in 목적의 AlarmLow가 명칭으로 생성된다. 참고로 메트릭은 데이터 수집이 적어도 1분의 interval을 갖는 대상을 선택하기를 권고한다. 너무 긴 interval은 급격한 트래픽 변경에 빠르게 대응하기 어려워지기 때문이다. AlarmHigh는 사용자가 입력한 CPU, RAM Usage 70%로 설정된다. 반면에 AlarmLow는 설정값보다 10% 적은 63%로 설정된다. 이에 대한 설명은 위에서 언급한 레퍼런스에 다음과 같은 문장을 통해 확인할 수 있다:
“In this case, it slows down scaling by removing capacity only when utilization passes a threshold that is far enough below the target value (usually more than 10% lower) for utilization to be considered to have slowed.”
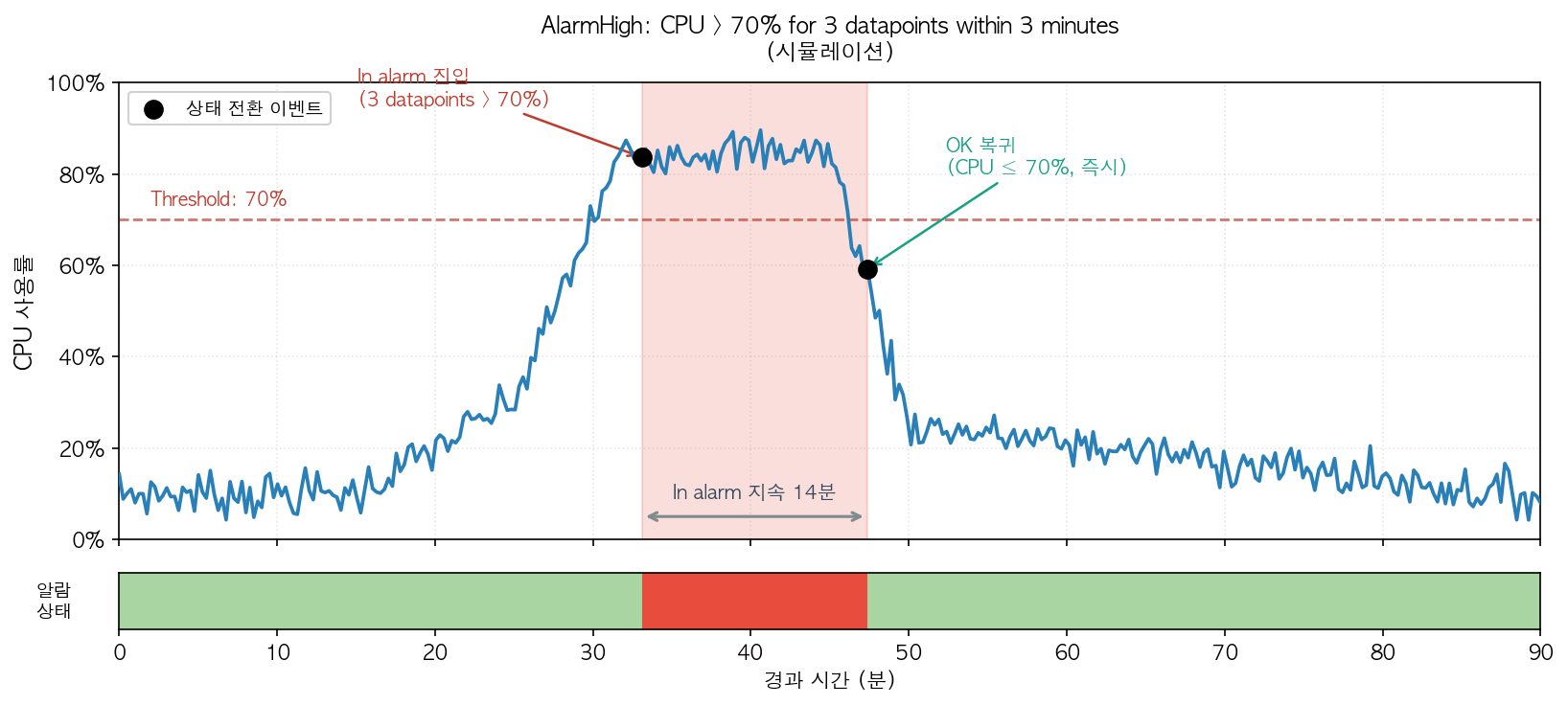
트래픽이 증가할 때 scale out은 사용자가 설정한 값(70%)에서 즉각 발생해야 한다. 반면 scale in은 트래픽이 충분히 안정화되었다고 판단될 때까지 보수적으로 미뤄지는데 그 기준을 목표값의 10% 이상 낮은 값(63%)에서 발생하게 한다. 각각 3분 동안 3개의 포인트, 15분 동안 15개의 포인트가 관찰되어야 알람 생성 조건이 충족된다5. 이 비대칭은 AWS에서 의도적으로 정한 것이다4.
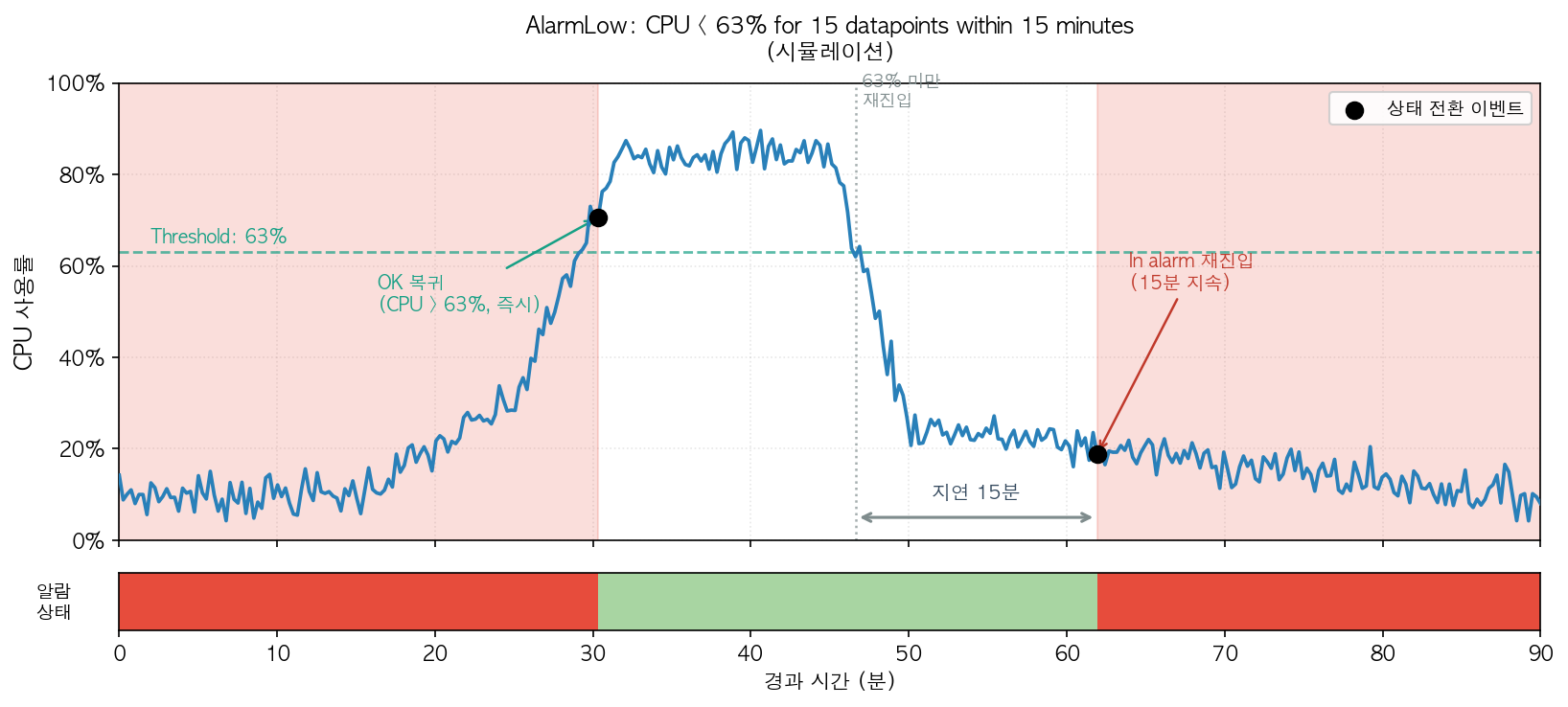
알람이 발생하면 Application Auto Scaling은 몇 개의 태스크를 만들면 현재 트래픽을 안정적으로 받아서 설정 값 밑으로 떨어질까를 계산한다. 이때 보수적으로 늘리면 트래픽이 한계치를 넘어서 발생하는 비용이 크기 때문에 즉각적일 수밖에 없다. 반면에 태스크를 줄이는 과정은 조심스러울 수밖에 없다. 불필요하게 최적화해서 즉각적으로 줄였을 때 발생하는 피해를 받는 것보다 줄이지 않아서 발생하는 비용이 더 낫기 때문이다.
마지막으로 계산된 desired count는 ECS Service로 전달되고 설정된 min/max 값에 따라 태스크의 개수가 조절된다.
태스크 1개 Abort 및 Scale Out 지연
테스트에서 80 threads로 설정해서 CPU가 93%에 도달했을 때 desired count는 2로 변경됐다. 하지만 태스크 1개가 abort되고 다른 태스크가 새로 생성되어 2대로 안착되는 현상을 확인했다.
참고로 프로덕션에 min/max를 4/8로 설정했지만 테스트에서 4개를 유지하는 건 비용 낭비이기 때문에 min/max 1/2로 설정해서 진행했다.
근본적인 원인은 grace period가 1분으로 되어 있었기 때문이다. 짧은 grace period는 부팅 시간이 긴 앱의 health check를 실패하게 만드는 원인이 된다. 결과적으로 ECS Service가 해당 태스크는 문제가 있다고 판단하여 죽이고 새롭게 띄운다. 첫 실험에서는 grace period 개념을 몰랐고 IaC 문법 익히는 데 너무 많은 무게를 두었기 때문에 충분한 레퍼런스 조사가 부족했다.
태스크 활성화까지의 시간을 고려한 Grace Period 설정
적절하지 않은 grace period는 태스크를 무한하게 뜨게 하여 서비스 자체를 마비시키는 결과를 일으킬 수 있다. 실제로 다른 팀에서 유사한 사례를 앞서 목격한 적이 있었다.
값을 설정하기 전에 grace period가 정확히 무엇인지 확인할 필요성이 있었다. AWS 문서에서 “after a task has first started”6로 언급되어 있는데 이것이 컨테이너가 띄워지는 시점부터 인지, 아니면 트리거가 시작되는 시점인지는 불분명했다. 다른 AWS re:Post 문서에서 “When setting your grace period, consider all relevant factors, such as bootstrap time and time to pull container images.”7 라는 구절을 확인할 수 있었는데, 이미지를 가져오는 시간까지 고려해서 설정해야함을 나타낸다.
태스크 로그를 통해 첫 health check api가 찍히는 시점까지 약 4분 정도 걸렸고, 1 vCPU 사양을 바탕으로 스프링 앱 부팅 시 발생하는 로그 Started Application in에서 85~90 초 정도 걸림을 확인할 수 있었다. 따라서, 4분에는 부트스트랩, 이미지 풀링, 그리고 스프링 앱 부팅까지 포함하는 것이다. 이 과정은 테스트마다 태스크를 다시 scale in 하는 등의 초기화 과정이 오래 걸려 쉽지 않았다.
측정된 값(4분)으로 과최적화(Overfitting)를 했을 때 예기치 못한 또다른 문제가 발생할 수 있기 때문에 약간의 버퍼를 둬서 5분(300s)으로 결정했다.
Scale Out 후 트래픽 분산
grace period를 설정하고 재실험한 결과가 아래 그림과 같다.
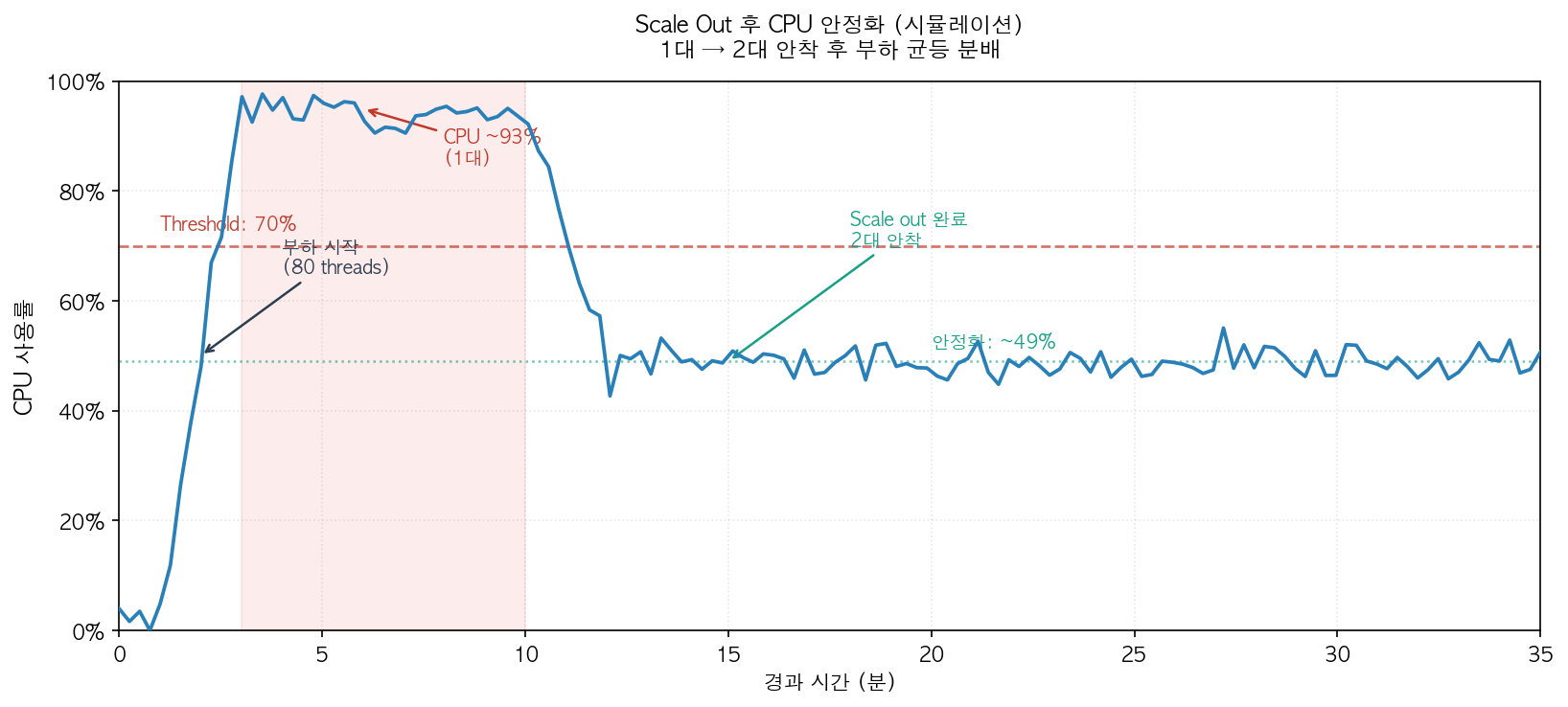
CPU usage 70% 이후로 3분 동안 3개의 포인트가 찍인 순간 알람이 발생했다. 해당 알람은 Application Auto Scaling에 전달되어 필요한 태스크가 계산된다. 계산된 태스크를 기반으로 desired counts를 업데이트하도록 ECS Service에 전달하면 ECR로부터 이미지를 풀링하고 컨테이너를 띄운다.
ALB가 스프링 앱의 헬스 체크 endpoint를 호출해서 성공하면 트래픽이 라우팅 되면서 부하가 분산됨을 확인할 수 있었다. 분산 직후의 CPU usage는 52.76%로 측정되었고, 평균적으로 49%에 도달했다.
Scale In 관찰
CPU usage 메트릭 기반의 scale in 동작은 큰 문제없이 동작했다. 앞서 보여준 AlarmLow 그림과 같이 63% 이하에서 15분 동안 15개의 데이터 포인트가 찍혔을 때 알람이 트리거 되었다. 사실 CloudWatch상으로는 그렇게 보였지만 실제로 scale in/out 둘다 약 2분 정도 알람이 울리기까지 지연이 있는 것으로 보인다.
구체적인 원인과 유사한 레퍼런스는 찾을 수 없었다. 게다가 여러번의 실험을 진행하면서 강제로 태스크를 종료시켜서 테스트 초기화를 하는 경우 그 이후 scale in/out이 오동작하였다. 제대로 된 테스트를 위해 완전히 재배포를 해야했다.
5. 운영 후 회고
RAM 기준의 문제
Auto Scaling을 막 적용한 이후의 운영은 큰 문제가 없었다. B2B 계약이 이뤄져도 HR 서비스 자체를 도입하면서 필요한 마이그레이션이나 추가적인 기능 개발을 해야하기 때문이다. 다만 서비스가 성장하면서 새로운 기능 추가는 RAM baseline을 지속적으로 높이는 결과를 초래했다. 이러한 RAM 문제를 이해하기 위한 JVM 학습을 통해 알아낸 내용은 다음과 같다.
먼저, JVM의 클래스 로딩은 Lazy loading을 따른다는 점이다. 배포가 막 이뤄지고 서비스 사용이 적은 상황에서는 RAM usage 자체가 낮게 시작하지만 시간이 지나면서 70%를 넘는 경우가 생긴다.
다음으로는 Garbage Collection(이하 GC)의 결과로 RAM usage 프로파일은 톱니바퀴 형태를 띤다는 것이다. 이는 JVM만의 특성은 아니고 GC가 있는 프로그래밍 언어에 모두 해당되는 내용이다. 즉 RAM usage가 높아지면 알아서 GC가 발생하고 usage가 낮아지는 형태를 보인다.
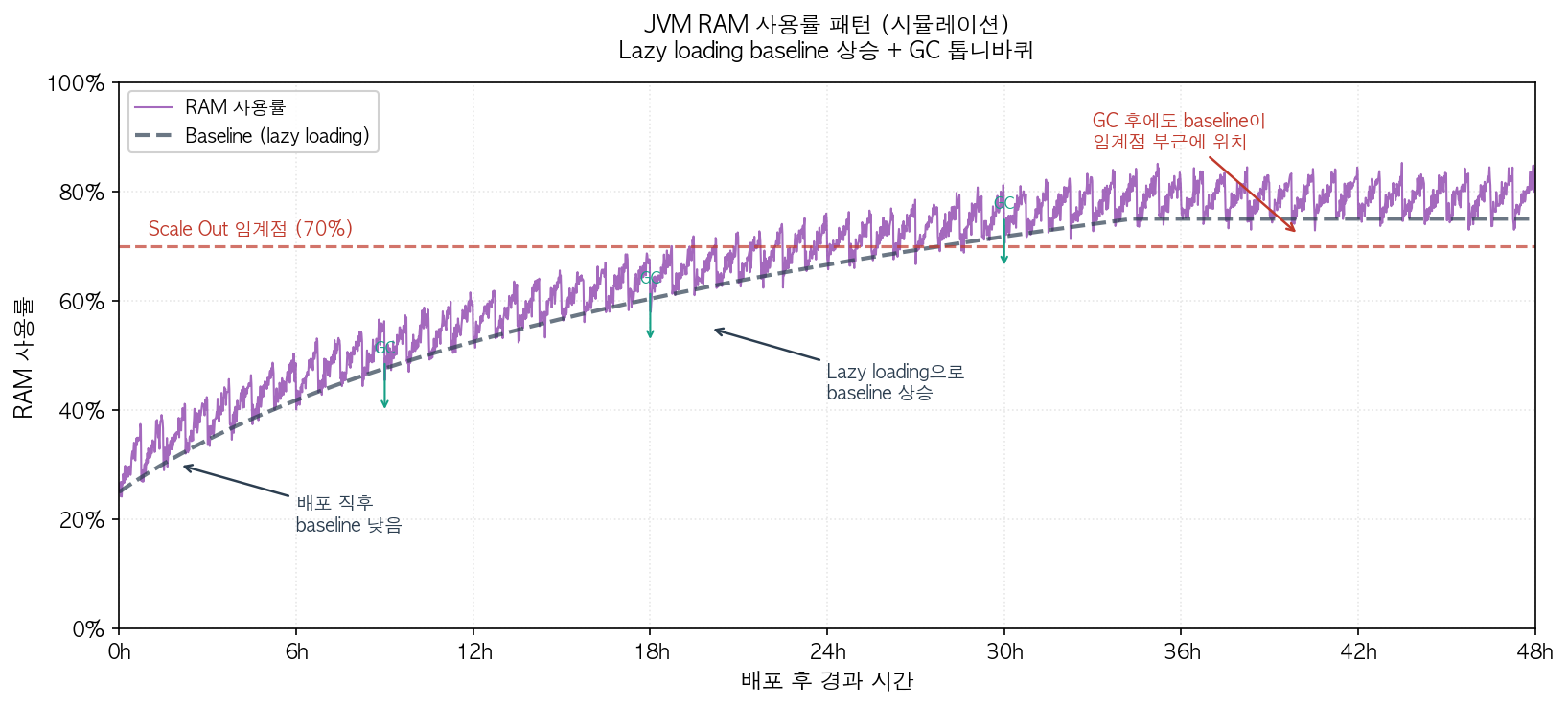
여기서 문제점은 Bean들은 ApplicationContext가 참조를 잡고 있기 때문에 GC의 대상이 될 수 없다는 점이다. 게다가 GC의 대상은 DTO와 같은 짧은 수명의 객체에 해당되는데 GC 전후의 차이가 63% 이하까지 내려갈 정도는 아니라는 점이 scale in을 전혀 발생시키지 않아 불필요한 태스크들이 떠있게 되었다.
AWS 공식 문서에서 Java 기반 서버는 애플리케이션의 사용률과 Memory 사용률이 비례하게 상승하지 않기 때문에 Memory를 메트릭으로 사용하는 것은 권고하지 않는다고 나와있다8. 다른 팀에서도 RAM 기반의 알람 메트릭은 제거하기로 결정했기 때문에 우리도 동일하게 진행했다.
근본 원인은 워크로드 미분리
사실 RAM usage가 늘어난 배경에는 워크로드가 분리되지 않았기 때문이라고 생각한다. 현재 서버는 API 트래픽과 백그라운드 작업을 모두 처리하고 있다. 만약 API와 Worker 서버를 분리했다면 하나의 단일 서버가 4개 운영되는 것이 아니라 각각 독립적인 태스크 min/max 설정과 scaling 정책을 적용 가능했을 것이다.
| CPU | RAM | 적합한 Scaling 메트릭 | |
|---|---|---|---|
| API 서버 | 트래픽에 비례, 출퇴근 스파이크 | Bean 로딩 후 안정적, 단명 객체는 GC로 회수 | CPU 사용률 |
| Worker 서버 | 큐 작업 시 간헐적 스파이크 | 배치 처리 중 대량 객체로 변동 큼 | consumer lag |
이러한 워크로드 분리 작업을 위해 팀원들에게 문제점과 함께 해결방안을 제시해둔 상태다.
지금 다시 한다면
동일하게 70%의 목표값을 사용하되 RAM 메트릭은 처음부터 빼거나 높게 잡았을 것이다. 게다가 워크로드를 분리하기 쉽게 처음부터 멀티모듈로 구성하여 코드 베이스 자체도 분리하여 작성하도록 팀에 제안했을 것이다.
JMeter 기반의 수동 테스트보다는 부하 시나리오를 자동화하고 CPU 뿐만 아니라 응답시간(p50/p95/max)도 함께 측정했을 것이다. 부팅 시간 자체도 줄이는 방안을 검토해봤을 것이다. 현재 부팅 속도로는 트래픽 스파이크를 감당할 만큼 빠르게 반응할 수 없을 것으로 보인다.
-
CPU 사용률을 기반으로 확장 — Google Cloud Docs. 초기화가 오래 걸리는 앱은 85% 이상 비권장. ↩︎
-
Target tracking scaling policies for Amazon EC2 Auto Scaling — AWS Docs. 원문: “To use resources cost efficiently, set the target value as high as possible with a reasonable buffer for unexpected traffic increases.” ↩︎
-
Apache JMeter — Apache Software Foundation. 오픈소스 부하 테스트 도구. Java 기반으로 웹 애플리케이션의 성능 측정 및 부하 테스트를 지원. ↩︎
-
Target tracking scaling policies for Application Auto Scaling — AWS Docs. Application Auto Scaling이 CloudWatch 알람을 자동 생성/관리하는 메커니즘 설명. 특히 “How it works”, “Considerations” 섹션 권장. ↩︎ ↩︎
-
aws/containers-roadmap#638 (comment) — Target tracking policy가 자동 생성하는 CloudWatch 알람의 기본 datapoint 설정: AlarmHigh 3 datapoints/3분, AlarmLow 15 datapoints/15분. ↩︎
-
Amazon ECS service definition parameters — AWS Docs. healthCheckGracePeriodSeconds: “after a task has first started” 시점부터 health check 실패를 무시. 기본값 0초. ↩︎
-
Troubleshoot functioning ECS tasks marked as unhealthy — AWS re:Post. grace period 설정 시 bootstrap time과 container image pull time을 모두 고려하라고 안내. ↩︎
-
Auto Scaling 모범 사례 — AWS ECS Developer Guide. “Java 기반 서버” 섹션: JVM은 컨테이너 메모리에 맞춰 힙을 최대한 크게 잡으므로 메모리 사용률이 애플리케이션 사용률에 비례하지 않으며, “메모리 사용률에 따라 Java 기반 서버를 확장하지 않는 것이 좋"다고 권고. ↩︎