Virtual Thread 적용 이후 대량 이벤트 발생시 DB 저장 로직 실패
진행중인 개인 프로젝트에서는 DART 전자공시를 이용한다. 매일 수백 개의 전자공시가 DART 전자공시를 통해 게시되며 이를 수집해서 필터링하고 시장의 반응과 LLM의 감성분석을 집계하는 목표를 갖고 있다.
공시 자료 폴링(Polling)이 중단되었다가 재시작 하는 경우 다량의 공시자료를 조회하고 이벤트를 발행하게 된다. 이때 분석된 결과를 DB에 저장하는 과정에서 이슈가 발생했다. 이 과정의 비즈니스 로직은 아래와 같이 정리할 수 있다.
- Polling으로 새 공시를 수집한다.
- 수집된 공시의 제목으로 후속 처리가 필요한지 필터링한다.
- 후속 처리가 필요하면 NewDisclosureEvent를 발행한다.
- 이벤트 메시지에 담긴 공시 번호로 공시 문서를 조회한다.
- 조회된 공시 문서를 LLM에게 넘겨서 감성 분석(Sentiment Analysis)을 실시한다.
- 분석 결과를 DB에 저장한다.
문제가 발생한 코드는 다음과 같다.
Before - AnalysisEventListener
public void handle(NewDisclosureEvent event) {
String content = dartClient.fetchDocumentContent(...);
analysisService.analyze(...);
disclosureRepository.updateStatus(...);
}
Before - AnalysisService
@Transactional
public void analyze(...) {
AnalysisResult result = llmClient.analyze(...);
analysisReportRepository.save(report);
}
감성 분석 결과가 DB에 저장되지 않는 현상을 확인했고 가상 스레드 도입이 원인으로 추측되었다.
원인 분석
플랫폼 스레드를 사용하는 경우 대량 트래픽이 발생하면 톰캣 스레드풀이 백프레셔 역할을 할 수 있다. 하지만, 가상 스레드를 적용하는 순간 스레드 생성 비용이 낮아져 대량 스레드가 제한 없이 생성될 수 있다. 말 그대로 수도꼭지를 틀어놓고 한없이 물을 받아놓는 상황에 비유할 수 있다.
물론 이벤트 발생시 가상 스레드의 도움으로 즉각적인 데이터 I/O는 구현 의도에 맞다. 이벤트 발생 시점의 주가를 지연없이 추적해서 LLM의 공시자료 분석결과와 시장 반응을 비교해서 인사이트를 얻는게 목표였기 때문이다.
Synchronized 블록에서 pinning이 원인일까?
가장 먼저 의심했던 부분은 Synchronized 블록에서 pinning 되는 문제였다. Java 21에서 발생한다는 여러 아티클들을 읽어본 기억이 있기 때문이다. 서비스 로직에서는 사용하지 않았기 때문에 라이브러리 중 하나가 가상 스레드 호환이 안 좋을 것으로 생각했다. 그 중 하나로 HikariCP를 먼저 확인했다.
흥미롭게도 커넥션을 가져오는 과정에서 Synchronized는 찾을 수 없었다. HikariCP가 DB 커넥션을 얻기까지의 동작 과정은 다음과 같다:
- HikariPool 클래스의 getConnection 메서드 호출
- 타임아웃 전 While문을 돌며 ConcurrentBag에서 PoolEntry를 꺼내기 시도(borrow)
- ConcurrentBag 클래스의 borrow 메서드에서 스레드로컬 리스트를 가져오기
- 리스트를 돌면서 CAS연산으로 캐시된 STATE_NOT_IN_USE인 커넥션을 찾기
- 있으면 반환, 없으면 sharedList 순환하면서 커넥션을 찾는다. (여기서도 CAS 연산을 사용)
- sharedList에도 없으면 While문을 돌면서 handoffQueue에서 대기하며 바통터치를 기다린다
- 타임아웃(디폴트 30초)이 발생하면 SQLTransientConnectionException을 던진다
여기서 3번과 4번은 가상스레드 입장에서 무의미하다. 스레드로컬 리스트를 불러오는 이유는 sharedList를 순환하면서 커넥션을 찾는 과정이 CAS 경합(Contention)를 일으킬 수 있기 때문에 스레드로컬이라는 저장소에 캐싱된 커넥션을 찾으려는 시도다. CAS 경합은 스레드 개수가 많아질수록 재시도 횟수가 늘어나 성능이 저하된다.
하지만 가상스레드는 사용하고 제거되기 때문에 다음에도 동일한 스레드가 오지 않는다. 결국 캐시히트가 발생할 수 없는 상황이다. 게다가 HikariCP PR #2055에서 “Synchronized 블록에서 Carrier Thread가 Pinning 되니까 ReentrantLock으로 바꾸자"는 논의를 확인할 수 있었다.
해당 PR은 결국 머지되지 않았는데 핵심은 “Pinning이 문제가 되려면 Synchronized 블록 안에서 가상 스레드가 park되어야 하는데, I/O 없이 단순 연산만 하면 Synchronized 블록도 문제없다” 였다. Synchronized 자체에서 발생하는 문제가 아닌 Synchronized와 블로킹 I/O 조합이 문제인데 HikariCP 내부에는 그 조합이 없다는 주장이다.
커넥션 풀 고갈로 HikariCP 타임아웃
7번 상황에서 발생할 수 있는 로그가 실제로 발생했다. 커넥션 풀의 크기와 타임아웃은 각각 10, 30s로 아래 로그와 코드 그리고 설정이 정확히 일치함을 확인할 수 있다.
HikariPool-1 - Connection is not available, request timed out after 30041ms
(total=10, active=10, idle=0, waiting=25)
문제가 발생하는 위치는 HikariCP가 아닌 내가 작성한 코드에 있었다. 위에서 언급한 코드를 다시 확인해본다.
@Transactional
public void analyze(...) {
AnalysisResult result = llmClient.analyze(...);
analysisReportRepository.save(report);
}
NewDisclosure 이벤트 발생 직후 분석을 진행한다. 이때 analyze 메소드가 트랜잭션을 시작한다. llmClient를 호출해서 외부 I/O가 발생하고 받아온 응답을 AnalysisReportRepository에 저장한다. 바로 이 부분을 에이전틱 코딩을 이용해서 작성했기 때문에 미처 확인하지 못한 부분이다.
에이전틱 코딩과 휴먼 에러
왜 이 부분이 문제가 될까? 지금까지 확인한 정보들을 종합해볼 수 있다. 먼저 롱 트랜잭션은 반드시 피해야한다. llmClient라는 외부 I/O는 롱 트랜잭션을 야기한다. 이때 수백 개의 가상 스레드가 해당 메소드로 진입하기 위해 커넥션 풀을 얻으려고 한다. 먼저 도착한 10개의 가상 스레드는 LLM의 분석 결과를 받아 저장하기 까지 하나하나가 오래 걸리니 커넥션을 기다리는 수백 개의 가상 스레드들이 결국 타임아웃이 발생하게 된다.
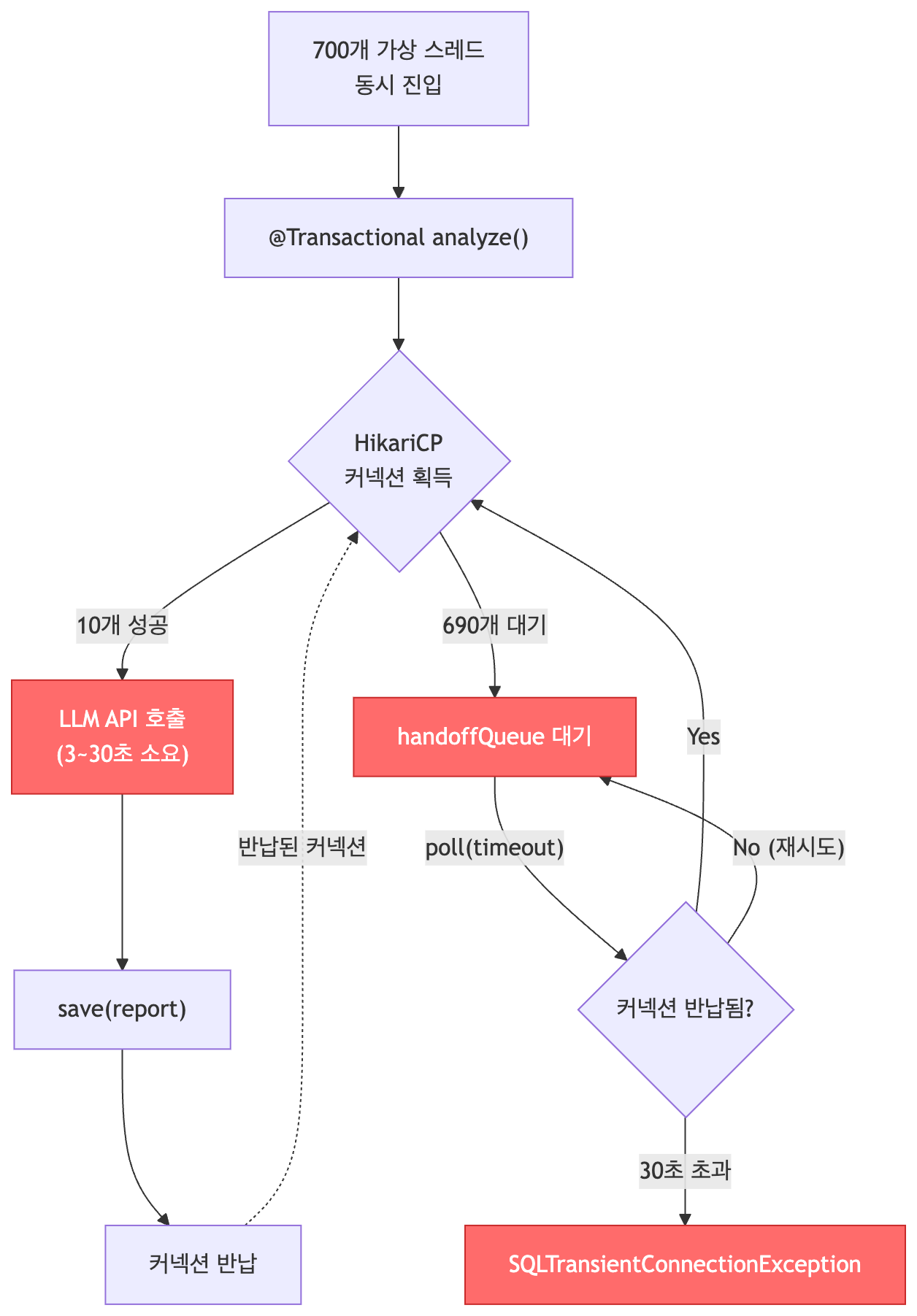
비유를 하자면 수백명의 직장인(가상스레드)들이 점심시간(타임아웃)에 은행 업무를 보기 위해 은행에 방문했다. 대기표를 뽑아서 기다리는데 창구(DB커넥션)는 10개 밖에 안된다. 창구에 있는 각 직장인(가상스레드)들은 서류작업 등을 미리 해두었으면 빠르게 해결되는데 창구(DB 커넥션)을 붙잡고 갑자기 외부에 전화(외부 I/O)를 하거나 서류를 정리하기 시작한다. 실제 창구에서 필요한 은행업무는 짧지만 직장인들이 불필요한 작업으로 오래 붙잡고 있기 때문에 나머지 수백명은 결국 점심시간(타임아웃)이 끝나고 다시 회사로 돌아간다.
실패하는 테스트로 이슈 재현
확인한 문제를 재현하기 위해 실패(Red)하는 테스트 코드를 먼저 작성했다. LLM호출의 응답속도를 5초로 가정하고 가상스레드는 700개로 테스트했다.
재현 테스트 (Red)
@Test
void shouldThrowSQLTransientConnectionException() {
// given - LLM API 응답 지연 시뮬레이션
given(llmClient.analyze(anyString(), anyString(), anyString()))
.willAnswer(invocation -> {
Thread.sleep(5_000);
return new AnalysisResult(Sentiment.POSITIVE, 0, "summary");
});
// when - 700개 가상 스레드 동시 실행
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
List<? extends Future<?>> results = IntStream.range(0, 700)
.mapToObj(i -> executor.submit(() ->
sut.analyze((long) i, "receipt-" + i, "삼성전자", "사업보고서", "content")))
.toList();
// then - 커넥션 풀 고갈로 일부 실패
List<Exception> exceptions = new ArrayList<>();
results.forEach(result -> {
try { result.get(); }
catch (Exception e) { exceptions.add(e); }
});
assertThat(exceptions).isNotEmpty();
assertThat(exceptions.stream()
.allMatch(e -> getRootCause(e) instanceof SQLTransientConnectionException))
.isTrue();
}
테스트 결과로 HikariCP 코드 분석하면서 확인한 SQLTransientConnectionException을 확인할 수 있었다.
해결
처음에는 세마포어를 도입하려고 했다. 세마포어(semaphore)는 HikariCP에 접근하는 스레드 수를 제한하면 외부 I/O로 최신 데이터를 가져오는 실시간성을 헤치지 않으면서 내부 시스템을 보호할 수 있다. 하지만 세마포어를 도입할 때 경계를 결정하는 복잡성이 증가하는 점과 유지보수성이 낮아지는 점이 각각 우려되었다.
HikariCP 분석을 통해 세마포어 도입보다 트랜잭션 경계 분리라는 더 간단한 해결책을 발견했다. 즉, 롱 트랜잭션 자체를 제거하면 세마포어가 불필요하다.
트랜잭션 경계 분리로 롱 트랜잭션 제거
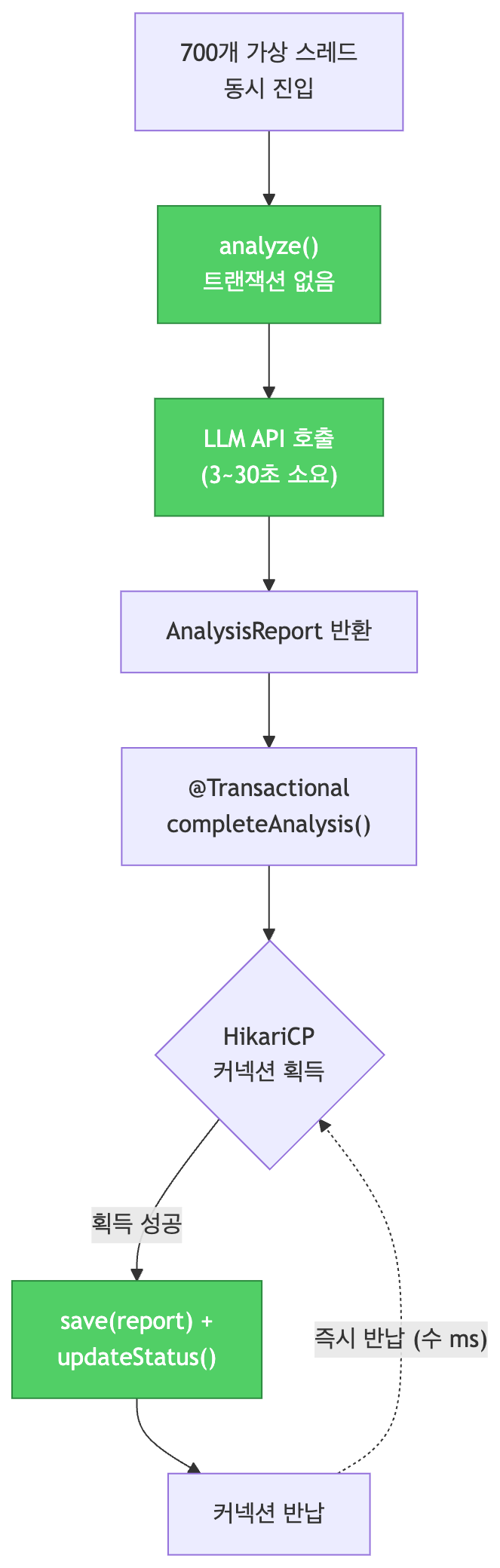
먼저 AnalysisService 클래스의 analyze 메서드에서 트랜잭션 어노테이션을 제거했다. 해당 메서드는 분석결과만 가져와서 반환하면 되며 외부 I/O를 통해 데이터만 받아오면 되기 때문에 트랜잭션과 통합될 필요 없다. 하지만 추후에 실패할 경우를 대비해서 리트라이나 타임아웃을 적용해서 At-least-once를 보장하기 위한 작업을 해야한다.
public class AnalysisService {
public AnalysisReport analyze(
Long disclosureId,
String receiptNumber,
String corporateName,
String title,
String content
) {
AnalysisResult result = llmClient.analyze(corporateName, title, content);
return AnalysisReport.builder()
.disclosureId(disclosureId)
.receiptNumber(receiptNumber)
.corporateName(corporateName)
.title(title)
.sentiment(result.sentiment())
.score(result.score())
.summary(result.summary())
.analyzedAt(LocalDateTime.now())
.build();
}
분석 리포트를 받는 쪽은 공시 분석 파사드 클래스인 DisclosureAnalysisFacade다. 기존의 리스너 메서드에서는 이 퍼사드 클래스에 분석을 위임하기만 한다.
public class DisclosureAnalysisFacade {
private final DartClient dartClient;
private final AnalysisService analysisService;
public void execute(
Long disclosureId,
String receiptNumber,
String corporateName,
String title
) {
log.info("새 공시 분석 시작: {} - {}", corporateName, title);
try {
String content = dartClient.fetchDocumentContent(receiptNumber);
AnalysisReport report = analysisService.analyze(disclosureId, receiptNumber, corporateName, title, content);
analysisService.completeAnalysis(report);
log.info("공시 분석 완료: {} - {}", corporateName, title);
} catch (Exception e) {
log.error("공시 분석 실패: disclosureId={}, {} - {}", disclosureId, corporateName, title, e);
}
}
}
이후 필요한 작업은 공시의 상태를 ‘분석완료’로 업데이트하기와 공시 분석 결과를 저장하는 작업이다. 이 두 로직은 원자적으로 처리해야 하기 때문에 completeAnalysis 메서드에 트랜잭셔널 어노테이션 붙여서 묶어서 처리했다. 해당기능을 별도로 클래스로 분리할지 고민했지만 당장은 복잡도가 낮아 분리할 필요성이 없다고 판단했다.
@Transactional
public void completeAnalysis(AnalysisReport report) {
analysisReportRepository.save(report);
disclosureRepository.updateStatus(report.getDisclosureId(), DisclosureStatus.ANALYZED);
}
결과
테스트 코드도 아래와 같이 변경하였다. LLM 분석 뿐만 아니라 공시 문서를 가져오는 I/O 작업도 모킹하여 처리했다. 테스트 수행 결과 모든 스레드가 에러 발생없이 통과됨을 확인할 수 있었다.
@DisplayName("커넥션 풀 고갈로 인한 SQLTransientConnectionException이 발생하지 않는다")
@Test
void shouldNotExhaustConnectionPool() {
// given
given(llmClient.analyze(anyString(), anyString(), anyString()))
.willAnswer(invocation -> {
Thread.sleep(5_000);
return new AnalysisResult(Sentiment.POSITIVE, 0, "summary");
});
given(dartClient.fetchDocumentContent(anyString()))
.willAnswer(invocation -> {
Thread.sleep(400);
return "content";
});
// when
ExecutorService executor = Executors.newVirtualThreadPerTaskExecutor();
List<? extends Future<?>> results = IntStream.range(0, 700)
.mapToObj(i -> executor.submit(() ->
sut.execute((long) i, "receipt-" + i, "삼성전자", "사업보고서")))
.toList();
List<Exception> exceptions = new ArrayList<>();
results.forEach(result -> {
try {
result.get();
} catch (Exception e) {
exceptions.add(e);
}
}
);
// then
Assertions.assertThat(exceptions).isEmpty();
}
배운 점
기능 위주의 명세로 AI 작업을 하다보니 트랜잭션 처리가 미흡했다. 사람의 개입이 필요한 부분은 적극적으로 개입하고 더 나아가 안정적인 에이전틱 코딩을 위한 트랜잭션 관련 컨텍스트 엔지니어링이 필요해 보인다.
검증된 라이브러리보다 진행 중인 프로젝트 코드를 먼저 의심했으면 디버깅이 오래 걸리지 않았을 것이다. 라이브러리보다는 변경된 내 코드를 먼저 들여다보는 과정이 필요하다.
학습하면서 롱 트랜잭션의 위험성은 여러번 들었지만 직접 경험하지 않아서 그 중요함을 깨닫지 못했다. 메소드 내에서 트랜잭션과 무관한 작업은 제외하고 트랜잭션 경계를 최소화하도록 한다.
참고한 자료
- Java의 미래, Virtual Thread | 김태헌 (2023, 우아한기술블로그)
- HikariCP PR #2055 - synchronized → ReentrantLock 논의 (거절)
- Virtual Threads | Oracle Java 21 Core Libraries