테스트 코드를 실무에 적용하면서 겪는 문제들
복잡했던 도메인 로직들이 리팩토링되고, 필요한 Fixture를 만들어두니 테스트 코드 작성 속도가 빨라지고 있다. 요즘은 매 스프린트마다 테스트 개수가 크게 증가하며, 하나 둘씩 관련 문제가 생기고 있다.
지난 포스트에서는 Application Context(이하 컨텍스트)의 증가1로 인해 MySQL로 연결되는 커넥션 수가 max_connections에 도달해서 발생하는 Too Many Connections을 다뤘다. 클래스마다 MockBean 조합이 다르면 Spring 컨텍스트의 캐시미스가 발생하여 Spring이 컨텍스트를 새로 만들기 때문에, MockBean을 통합하는 방식으로 해결할 수 있었다. 현재는 어드민 권한 테스트용 하나와 일반 유저 테스트용 하나의 컨텍스트로 총 2개만 유지되도록 매 스프린트마다 유지보수하는 중이다.
단위 테스트는 수 밀리초에서 끝나지만 통합 테스트는 오래 걸리기 때문에 전체 테스트 시간도 매 스프린트마다 점차 증가하는 추세다. 통합 테스트 환경을 구축하는 과정을 다룬 포스팅2에서는 데이터 클렌징 방식을 @Transactional 대신 테이블 TRUNCATE3을 채택했었다고 공유했다.
당시 테스트 자체가 없었기 때문에 시간 최적화에 대한 고려는 불필요했지만, 현재는 통합 테스트 하나하나의 수행 시간이 거슬리는 시점이 되었다. 따라서 이번 포스팅에서는 테스트 수행 시간에 관해 다뤄보며 겪은 경험과 결론을 공유해본다.
TRUNCATE을 사용한 클렌징은 어떤 문제를 발생시켰을까?
만약 느린 테스트 속도의 원인이 컨텍스트 캐시미스였다면, 테스트 메서드 한 건의 실행 속도가 느린 게 아니라 특정 클래스에 진입하기 전에 지연이 발생했을 것이다. 물론 지연은 있지만 이미 컨텍스트 개수를 2개로 관리하고 있었고 오래 걸리는 부분은 메서드 한 건의 수행 속도였다. 따라서 컨텍스트 캐시미스는 배제할 수 있었다.
통합 테스트마다 느리다면 모든 통합 테스트가 공통적으로 갖는 테스트 훅이 원인이라고 생각했다. 이 테스트 훅에는 TRUNCATE을 수행하는 메서드가 있다. 매 통합 테스트마다 어떤 일이 발생하는지 아래에 도식화했다.
flowchart LR
subgraph One["단일 테스트 1회"]
direction LR
S([시작]) --> H["@BeforeEach"]
H --> TR["TRUNCATE<br/>도메인 전체 테이블"]
TR --> B["테스트 본문<br/>(실제 사용 테이블은 일부)"]
B --> E([종료])
end
TR -.->|"테이블마다 DDL 수행"| DB[(MySQL)]
E ==>|"모든 테스트에서 반복"| S
classDef bottleneck fill:#fdecea,stroke:#c0392b,stroke-width:2px,color:#c0392b
classDef db fill:#eaf2fb,stroke:#2980b9,color:#2980b9
class TR bottleneck
class DB db
빨간색 박스로 된 부분이 예상되는 병목이었다. 테스트마다 생성되는 데이터는 전체 테이블에 비해 극히 일부이기 때문에 전체 테이블을 대상으로 TRUNCATE하는 것은 비효율적이라고 생각했다. 따라서 “실제로 TRUNCATE이 원인인가?”, “더 나은 방식은 없는가?” 에 답을 해보기 위해 테스트를 했다.
테스트 수행 시간 측정
테스트 케이스는 아래 표에 정리한 4가지로 결정했다:
| 실험 | Empty skip | Cleanup | 의도 |
|---|---|---|---|
| A (baseline) | TRUNCATE | 도메인 테이블 전수 TRUNCATE | |
| B | O | TRUNCATE | 빈 테이블은 SELECT 1 LIMIT 1 검사로 건너뛰기 |
| C | O | DELETE | DDL → DML 로 교체 |
| D (최종) | DELETE | DELETE에선 검사가 무의미해 probe 제거 |
Empty skip은 데이터가 담기지 않은 테이블은 과감히 클렌징을 생략함을 나타낸다. 추가로 클렌징 방법으로 TRUNCATE과 DELETE을 비교하였다. TRUNCATE은 DROP-CREATE으로 이해할 수 있는데 그 과정이 오버헤드가 있다면 DELETE으로 전환함으로써 얻는 속도 이점이 있을 것으로 예상했다.
인접한 두 케이스는 한 가지 변수만 바꿨다. 결과를 보면 어떤 시간적 차이가 어떤 변수에서 왔는지 분리해서 볼 수 있다. 예를 들어, A→B는 Empty skip의 효과를, B→C는 TRUNCATE과 DELETE의 차이를 보여준다. 아래 서브 섹션에서는 각 차이를 코드 관점에서 어떻게 구현했는지 볼 수 있다.
A → B (empty skip 추가)
public void cleanUpAll() {
jdbcTemplate.execute("SET FOREIGN_KEY_CHECKS = 0");
for (String tableName : tableNames) {
if (EXCLUDED_TABLES.contains(tableName)) continue;
+ List<Integer> probe = jdbcTemplate.queryForList(
+ "SELECT 1 FROM `" + tableName + "` LIMIT 1", Integer.class);
+ if (probe.isEmpty()) continue;
jdbcTemplate.execute("TRUNCATE TABLE `" + tableName + "`");
}
jdbcTemplate.execute("SET FOREIGN_KEY_CHECKS = 1");
}
빈 테이블이면 SELECT 1 LIMIT 1 만 던지고 TRUNCATE을 건너뛴다.
B → C (TRUNCATE → DELETE)
List<Integer> probe = jdbcTemplate.queryForList(
"SELECT 1 FROM `" + tableName + "` LIMIT 1", Integer.class);
if (probe.isEmpty()) continue;
- jdbcTemplate.execute("TRUNCATE TABLE `" + tableName + "`");
+ jdbcTemplate.update("DELETE FROM `" + tableName + "`");
TRUNCATE(DDL)에서 DELETE(DML)로 변경했다.
C → D (empty skip 제거, 최종 채택)
for (String tableName : tableNames) {
if (EXCLUDED_TABLES.contains(tableName)) continue;
- List<Integer> probe = jdbcTemplate.queryForList(
- "SELECT 1 FROM `" + tableName + "` LIMIT 1", Integer.class);
- if (probe.isEmpty()) continue;
jdbcTemplate.update("DELETE FROM `" + tableName + "`");
}
probe 블록 3줄을 들어내고 DELETE 한 줄만 남겼다.
측정 결과
Testcontainers가 띄워져 있는 상태 및 IntelliJ IDEA Run 환경에서 3회 평균을 구했다. 결과는 아래 그림과 테이블에 정리했다. 각 케이스는 실측 전 warmup 1회를 실행했다.
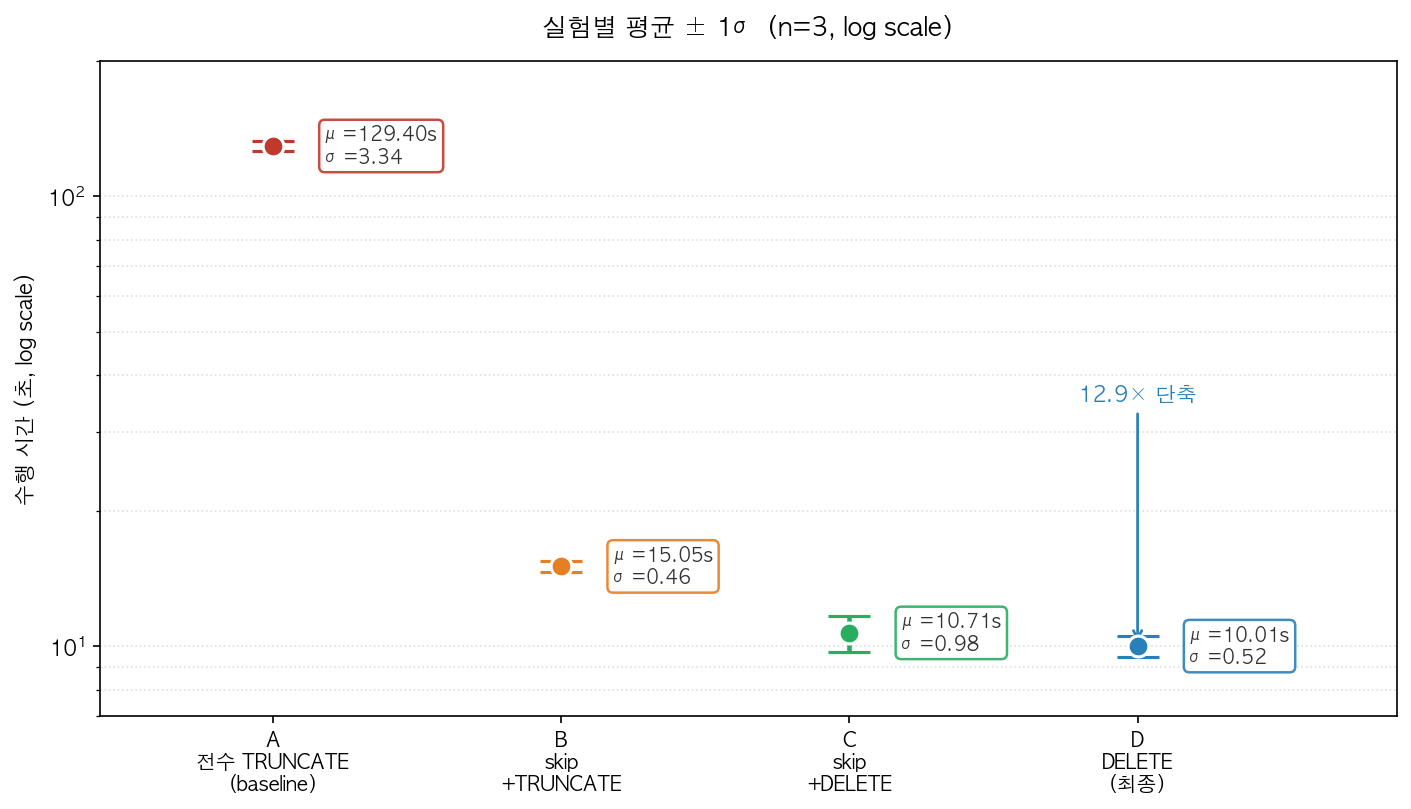
그림 1. cleanup 전략별 통합 테스트 수행 시간. JUnit testsuite time 합산, warmup 1회 제외 3회 평균 (실측).
| 실험 | 평균 (s) | σ (s) | vs A |
|---|---|---|---|
| A (baseline) | 129.40 | 3.34 | 1.00× |
| B (skip + TRUNCATE) | 15.05 | 0.46 | 8.60× |
| C (skip + DELETE) | 10.71 | 0.98 | 12.08× |
| D (DELETE, 최종) | 10.01 | 0.52 | 12.93× |
A에서 B로 빈 테이블을 제외하기만 해도 약 8.6배 빨라졌다. TRUNCATE에서 DELETE으로 전환한 결과(B→C)도 약 30% 더 빨라졌고, probe 검사를 제외한 D가 가장 짧고 빠른 결과를 냈다. 분산도 함께 좁아져(σ: 3.34 → 0.5 대) 실행 간 편차도 같이 줄었다.
트레이드오프
@Transactional 사용하지 못한 이유
@Transactional은 굉장히 편리하지만 양면성이 있다. 트랜잭션 경계를 예측할 수 없는 경우 원하는 결과를 얻을 수 없기 때문이다. 예를 들어, MyBatis에서 BATCH session은 별도 SqlSession을 열어서 Spring이 관리하는 트랜잭션 밖에서 SQL이 실행된다. 또한, 비동기 처리를 포함하는 경우도 고려하여 테스트를 작성해야 하기 때문에 자동 롤백 효과를 신뢰하기 어렵다. 이런 환경에서는 트랜잭션 의존성을 끊고 매 테스트 직전에 데이터를 강제로 비워주는 이 글에서 제시한 방식(TRUNCATE, DELETE)이 안전하다.
DELETE, empty-skip 사용시 고려 사항
TRUNCATE은 테이블을 DROP-CREATE하는 효과와 동일하다고 했다. 이는 AUTO_INCREMENT를 사용할 때 장점으로 작용한다. 테스트는 테스트 간 독립성이 중요한데 TRUNCATE의 부수효과3로 AUTO_INCREMENT가 자동으로 리셋된다. 만약 DELETE을 사용한다면 이러한 부수효과를 누릴 수 없다. 실무에서 조심해야 할 포인트는 명시적으로 ID를 테스트에 주입하는 게 아닌 암묵적으로 AUTO_INCREMENT에 의존하게 되는 것이다. TRUNCATE을 사용하는 경우 자동으로 리셋되어 보장받을 수 있지만, 그렇지 않은 경우 테스트가 깨지게 된다. 이 또한 PK로 TSID/UUID를 사용하는 경우는 상관없다. 자연스럽게 명시적으로 값을 주입하는 방식으로 테스트를 작성하게 되기 때문이다.
empty-skip도 최적화에 용이하지만 문제가 발생할 수 있다. 로직 자체가 단순하기 때문이다. 빈 테이블이 된 원인이 테스트를 수행하지 않아서 발생한 건지 아니면 테스트 결과 빈 테이블이 된 건지 알 수 없기 때문에, empty-skip은 두 클렌징 방식 모두에서 잠재적인 문제를 발생시킬 수 있어 디버깅을 어렵게 할 수 있다. 따라서 꼭 통제된 환경에서만 사용해야 한다.
회고
최적화는 잠재적인 문제를 함께 들고 온다. 그래서 실무에서는 단순한 방식과 베이스라인을 두고 비교 측정하면서 통제된 환경에서 해야 한다.
-
Spring 통합 테스트의 다중 ApplicationContext로 인한 Too many connections — MockBean 차이로 같은 JVM 안에 컨텍스트가 여러 개 캐싱되며 MySQL
max_connections(기본 151)를 넘어 테스트가 실패했던 사례. ↩︎ -
좋은 테스트는 무엇인가? 레거시 시스템에 테스트 환경 구축 —
@Transactional자동 롤백 대신 매 테스트 전후로 도메인 테이블을 TRUNCATE하는 방식을 택한 배경. ↩︎ -
TRUNCATE TABLE — MySQL 8.0 Reference Manual — 테이블의 모든 row를 삭제하는 DDL 문. 내부적으로 테이블을 drop & recreate하기 때문에 row-by-row로 지우는
DELETE보다 빠르지만, 그 대가로 암시적 커밋이 걸려 롤백이 불가능하고DROP권한을 요구하며ON DELETE트리거도 발화되지 않는다. InnoDB에서는AUTO_INCREMENT가 초기값으로 리셋되고, 다른 테이블이 FK로 참조하고 있으면 실패한다. ↩︎ ↩︎