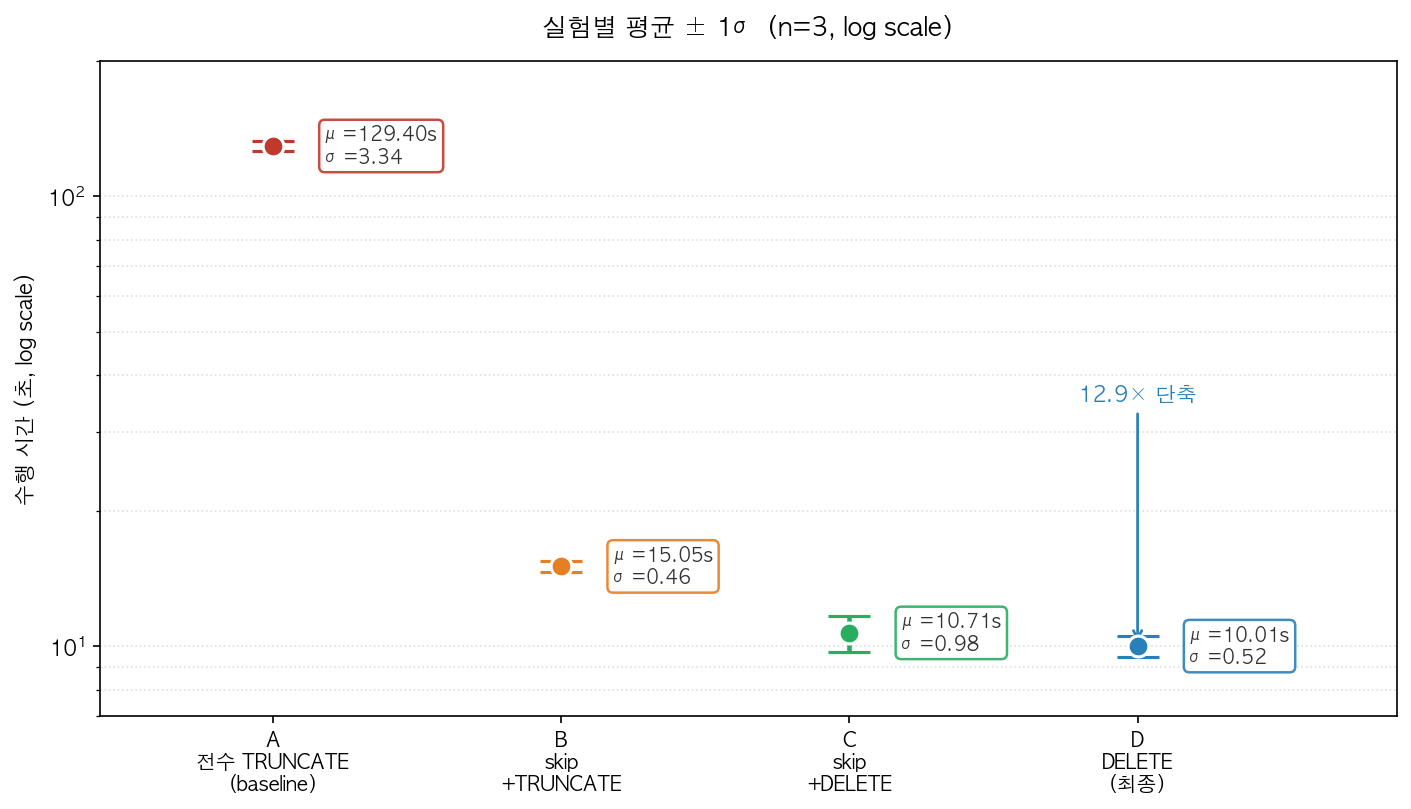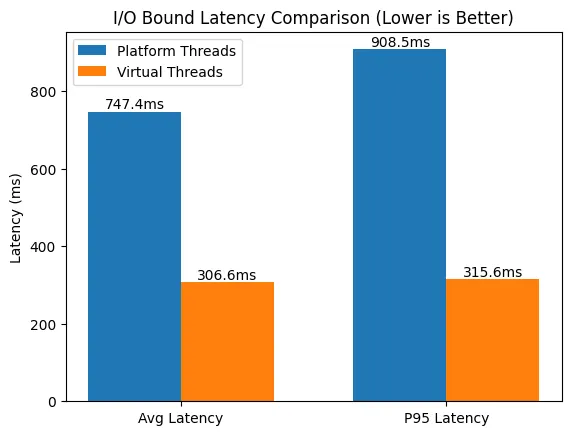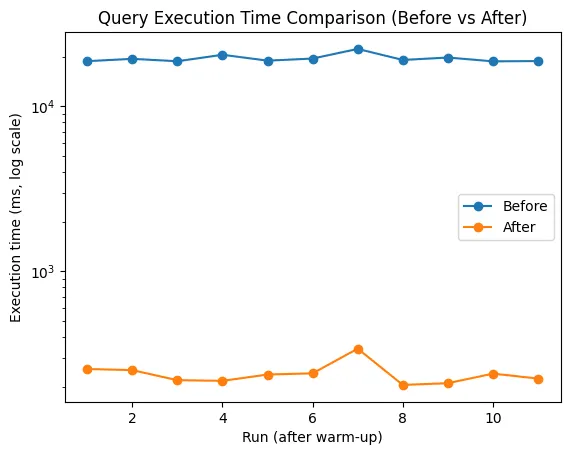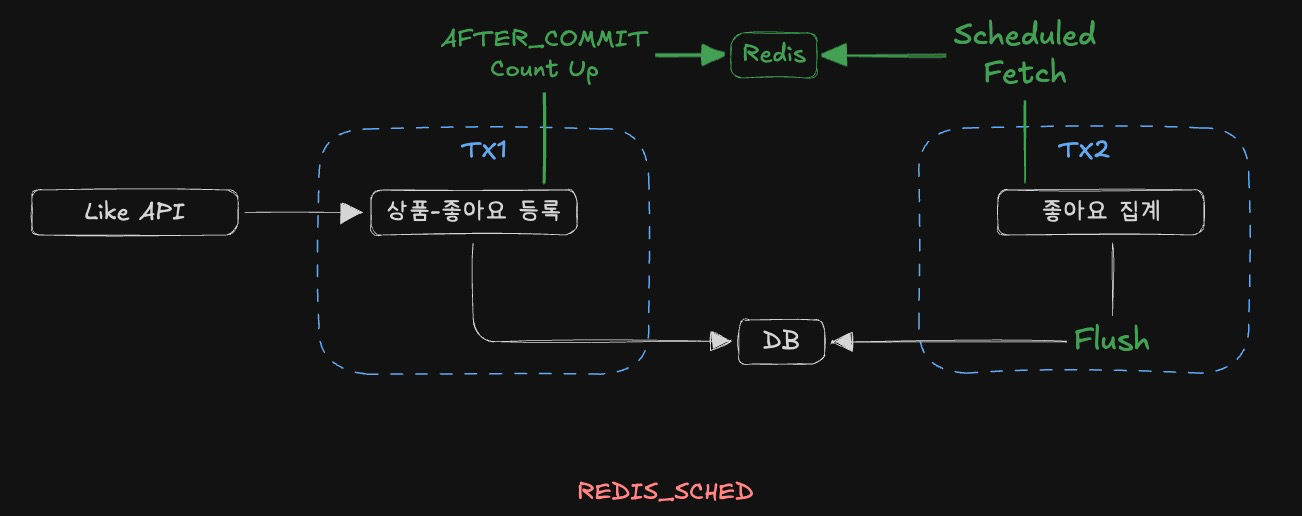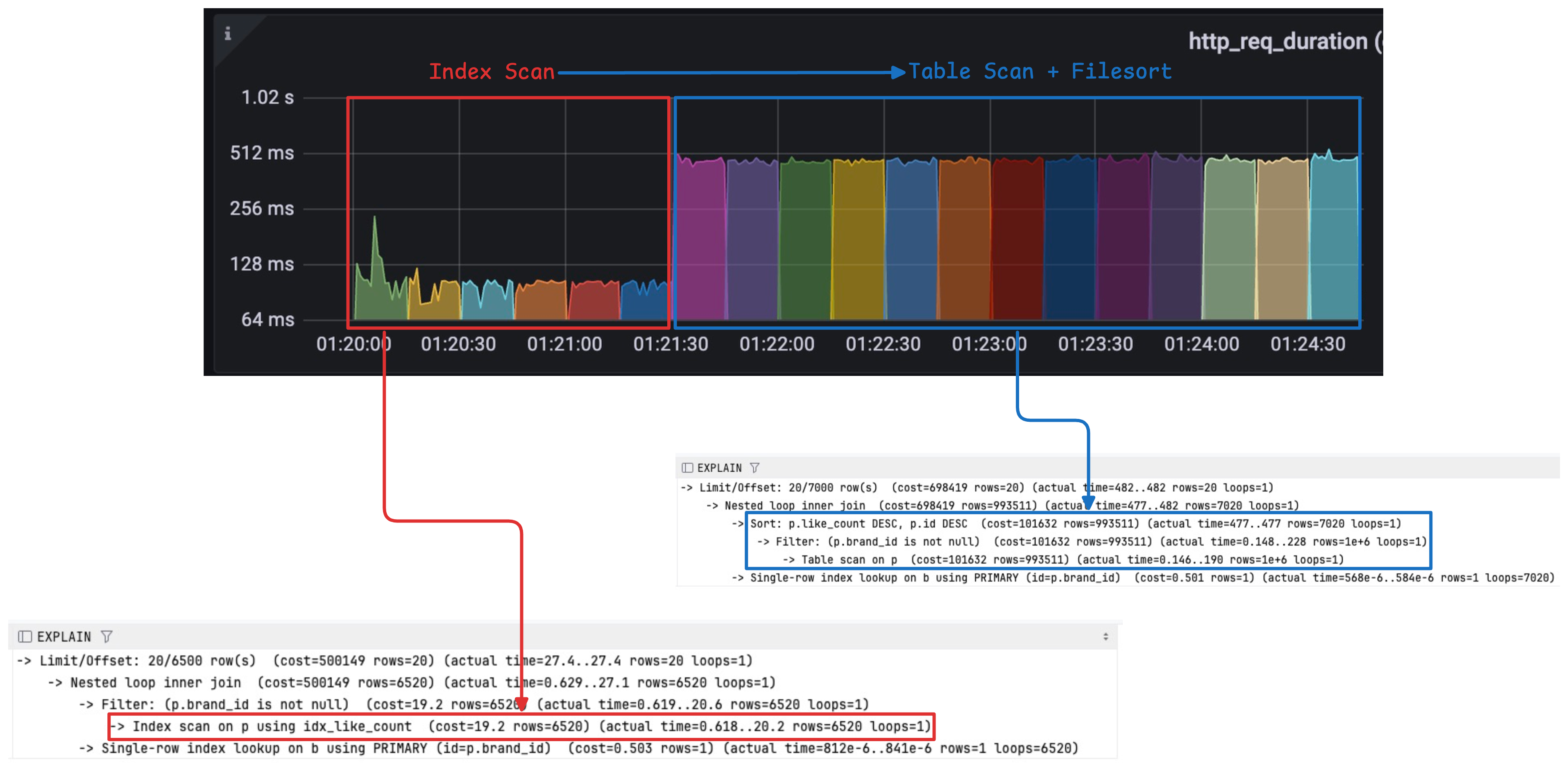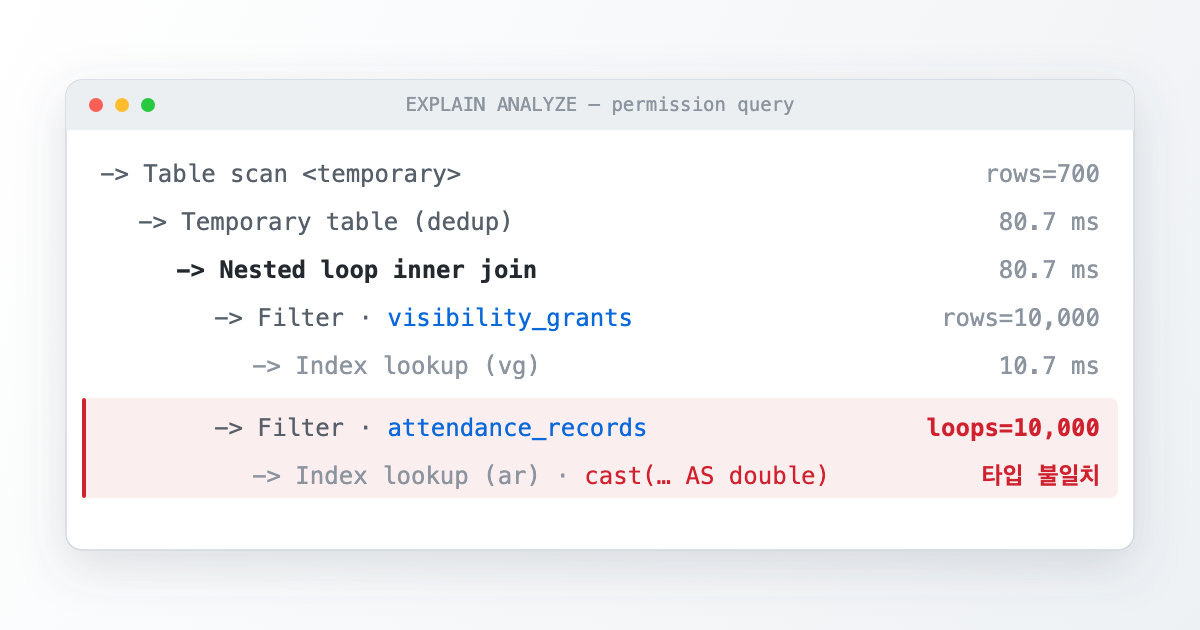
EXPLAIN ANALYZE로 슬로우 쿼리 읽기: 타입 불일치가 만든 10,000번의 반복 조회
LLM 시대에도 실행계획을 직접 읽어야 하는 이유 슬로우 쿼리 분석도 자동화되는 시대 요즘은 LLM을 이용해 슬로우 쿼리 분석을 자동화하려는 시도들이 많아지고 있다. 실행 로그를 모으고, SQL을 추적하고, EXPLAIN 결과를 해석하고, 개선안을 제안하는 흐름 자체가 점점 자동화의 대상이 되고 있다.1 그렇다면 개발자가 직접 실행계획을 읽는 능력은 덜 중요해질까? 나는 오히려 반대라고 생각한다. 자동화된 분석 결과를 신뢰하려면, 결국 사람이 그 판단을 검증할 수 있어야 한다. LLM이 “이 인덱스를 추가하세요”라고 말했을 때, 그 제안이 왜 맞는지, 혹은 왜 위험한지 판단하려면 실행계획을 읽는 감각이 필요하다. ...