요약
- 정규화 쿼리(집계 + 정렬) → 풀스캔 + filesort로 ~17초 소요.
- 역정규화 + 정렬 포함 인덱스 → ~227ms (약 76배 향상).
- OFFSET 페이지네이션 → 인덱스 순차 스캔 시작 → 임계점에서 Table Scan + Filesort로 전환 → 이후 응답시간 급등.
- 전환 전 일정한 속도는 InnoDB 버퍼 풀/캐시 히트율 덕분.
- Keyset(Seek) 페이지네이션 → 깊은 페이지에서도 일정 성능 (421ms → 31ms, 92.6% 단축).
- 인덱스 설계는 핫 트래픽 패턴(브랜드 + 인기순/최신순/최저가순)에 맞춘 3개의 복합 인덱스 유지가 가성비 최적.
- 설계 원칙: 필터 선두 → 정렬키 → tie-breaker(id)
- 캐시(Cache-Aside) 적용 시 200RPS에서도 DB I/O 부하 없이 ms 단위 응답 가능.
- 단, TTL·Evict 정책·실시간성 요구사항·정합성 유지·스탬피드 방지 등 고려 필수.
- 결론: 정규화/역정규화 → 인덱스 설계 → 페이지네이션 전략 → 캐싱이 단계적으로 맞물려 성능을 좌우함.
문제 정의와 가설
웹 서비스에서는 쓰기 보다 읽기 트래픽이 압도적으로 많다는 글을 읽거나 실제로 경험해봤을 것이다.
트래픽이 많다는 것은 서비스의 읽기 성능을 고려한 설계가 반드시 필요함을 나타낸다. 앱이 데이터를 읽기까지는 많은 변수들이 포함된다. 이러한 변수들은 네트워크 , 아키텍처, 어플리케이션, 데이터베이스 관점 등으로 접근할 수 있다.
이 글에서는 어플리케이션과 데이터베이스 관점에서 읽기 성능을 어떻게 향상시켜 안정적인 서비스를 운영할 수 있는지 테스트해보고 고민해보는 내용을 담았다. 역정규화와 정규화를 비교했으며, 인덱스 설계에 대한 고민 그리고 페이지네이션 전략에 대해 다루며 마지막으로 캐싱 전략을 나열하여 비교하고 적용된 결과를 바탕으로 테스트를 진행하였다.
목표로 하는 문제정의와 가설을 정리하면 다음과 같다 :
- 문제 정의
- “브랜드별 상품 목록을 인기순/최신순/최저가순으로 빠르게 제공하되, 깊은 페이지에서도 일관된 성능을 내고 싶다.”
- 가설
- 구조적(정규화/역정규화) + 물리적(인덱스) + 실행계획(OFFSET/Keyset) + 캐시가 연쇄적으로 성능을 좌우한다.
테스트 환경과 데이터 설계
모니터링과 아키텍처
테스트간의 비교를 위해 모니터링을 통한 수치비교는 필수라고 생각한다. 수치비교 뿐만 아니라 시간에 따른 메트릭 변화는 어떠한 인사이트를 얻기에 적합하기 때문에 적절한 모니터링 전략을 세우는게 필요하다.
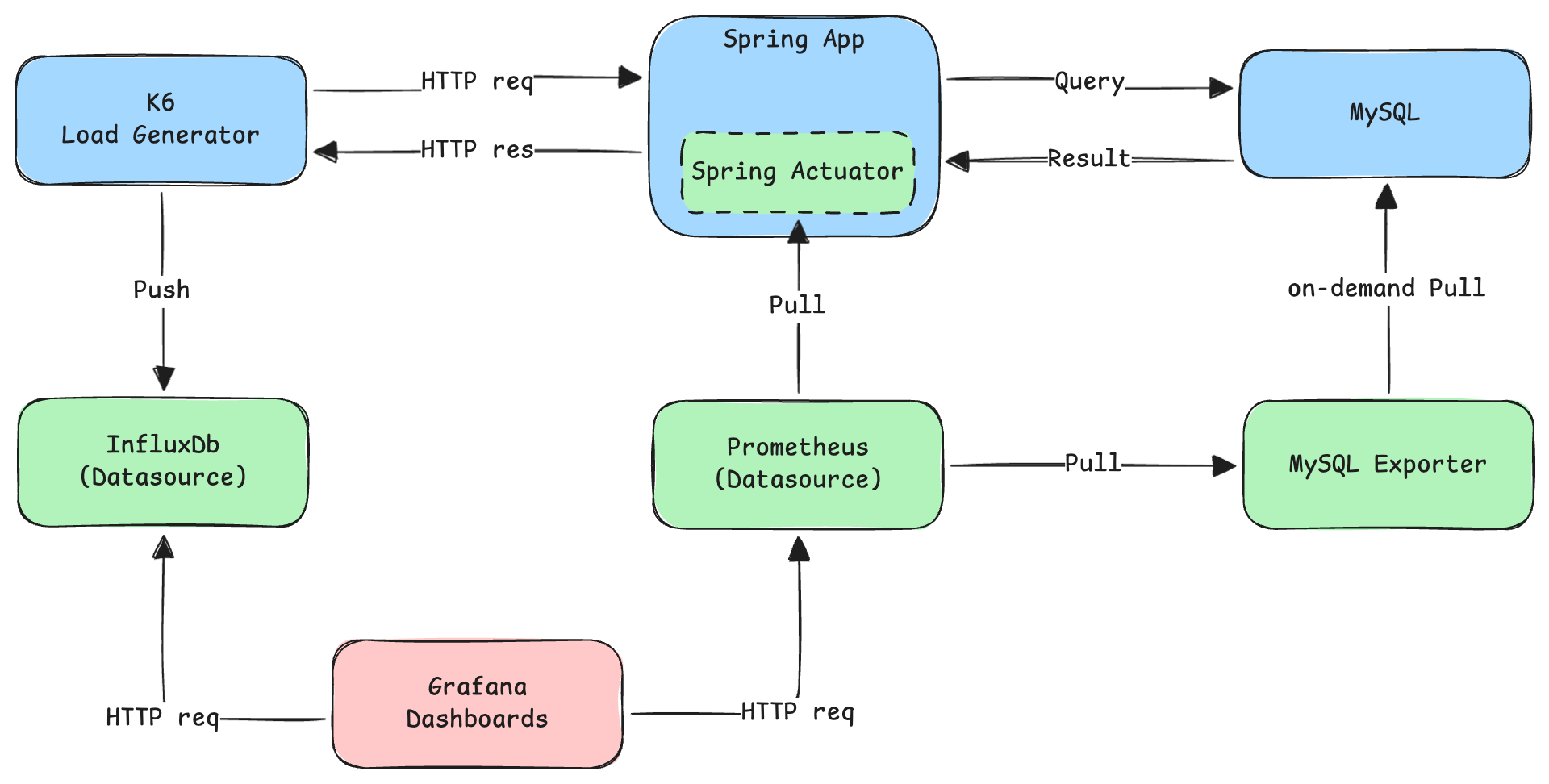
요청/응답 플로우 :
- K6에서 로드가 발생되어 스프링 앱에 요청한다
- 스프링 앱은 요청을 수행하기 위해 MySQL에 질의를 한다
- 결과가 K6에 반환되면 요청/응답 메트릭을 InfluxDb에 푸시한다
- Actuator와 MySQL Exporter는 각각 스프링, MySQL의 메트릭을 프로메테우스에 노출한다
- 프로메테우스는 주기적으로 메트릭을 pull해온다
- 그라파나는 InfluxDb와 프로메테우스를 데이터소스로 사용하며 HTTP 요청을 통해 주기적으로 렌더링한다
테스트 데이터 셋 생성전략
데이터 셋으로 테이블 마다 적절한 수를 배치하였으며, 테스트 종류와 시나리오에 따라 각각의 값을 조정하여 진행하였다. :
- brands : 20_000 (2만)
- products : 1_000_000 (1백만)
- product_likes : 10_000_000 (1천만)
생성 방법은 SQL, Python, shell script 등을 사용할 수 있으며 라이브러리 등이 존재한다. 여기서는 데이터 분포와 스크립트 이식성을 위해 Java로 정적 메서드를 작성하여 진행했다. 무엇보다 데이터 분포 설계를 적용하기에 유연성이 뛰어나다고 판단하였기 때문이다.
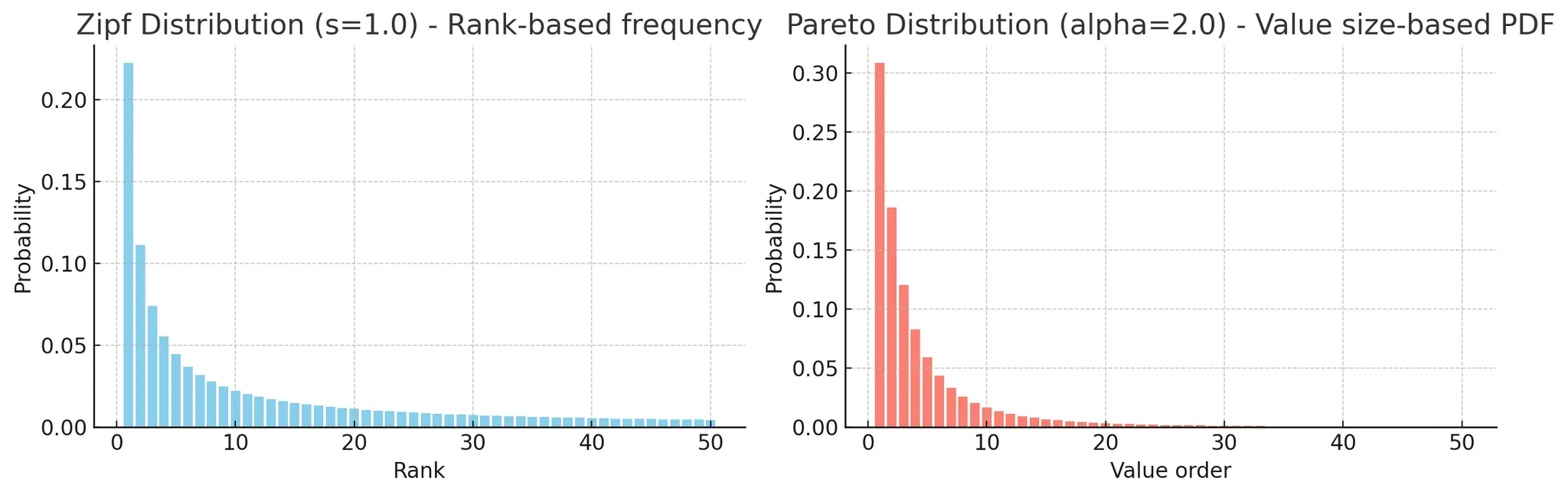
데이터분포에 대해 고민을 했다. 만약 테스트 셋이 균등한 데이터 분포를 갖는다면 옵티마이저가 동일하게 동작하지 않을까? 즉, 데이터 분포에 따라 실행계획이 달라지는 현상을 재현하기 위해 불균등한 데이터 분포를 선택했다.
여기서는 Zipf’s 분포를 이용하였다. Zipf’s 분포는 순위 기반 빈도 분포이며, 상위 몇 개가 전체를 지배하는 형태를 띈다. 실제로 SNS에서의 Celebrity Problem을 생각해보면 특정 셀럽에 좋아요 수나, 팔로우수가 많이 형성되어 실제 데이터와 유사성을 재현하고자 했다.
(참고로 아쉽게도 테스트 결과에서는 확인하기 어려웠다. 데이터 분포도 중요하지만 각 테이블의 설계나 데이터 크기도 영향을 미치는것 같다.)
집계 쿼리는 왜 17초가 걸렸나
상품 목록을 반환하는 API에서 각 상품의 ‘좋아요 수’를 반환해야 한다면 어떻게 해야할까?
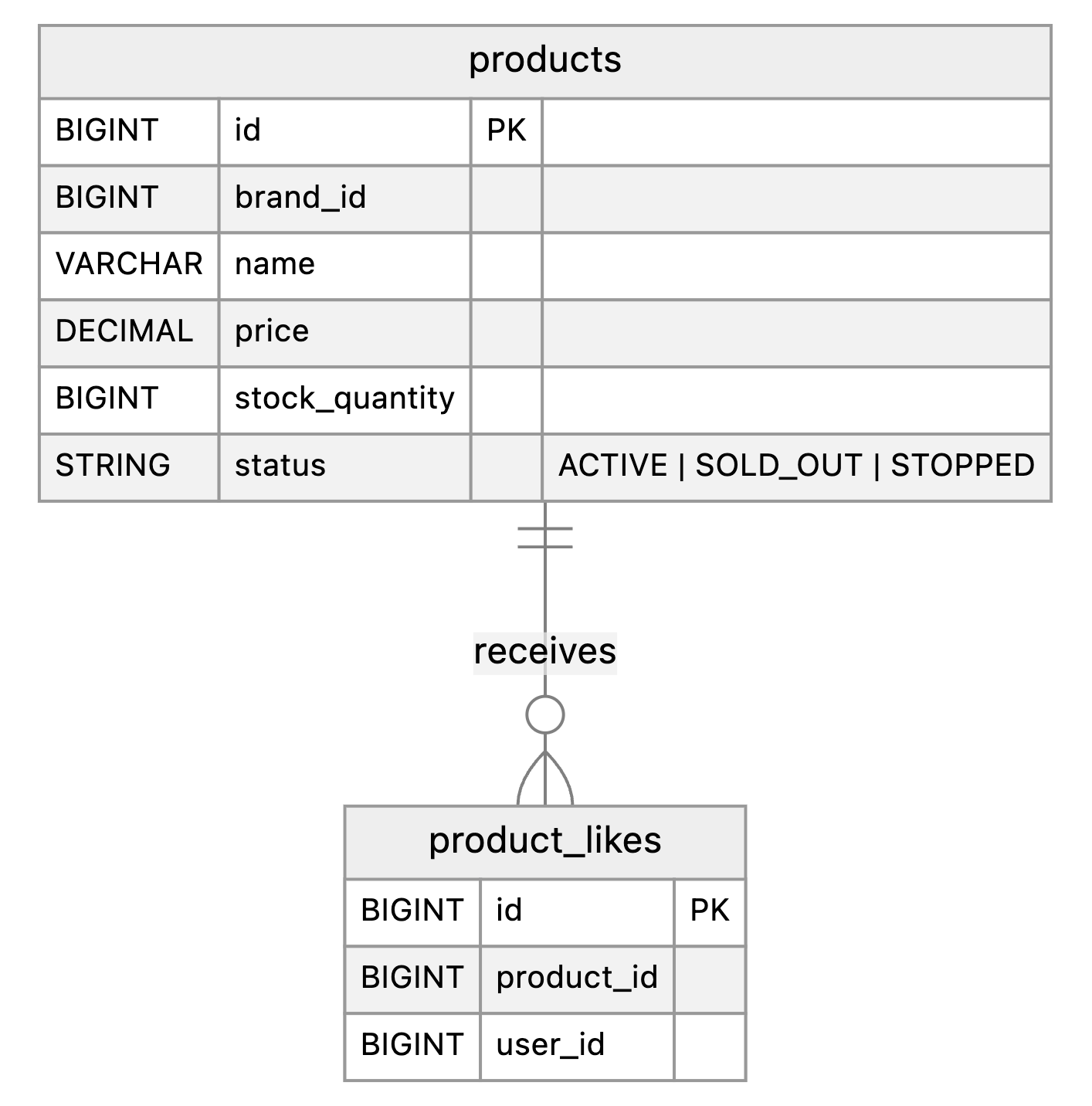
이 질문에 답하기 위해 ERD를 살펴본다.
유저가 상품에 좋아요를 하면 상품ID와 유저ID의 관계를 맺고 product_likes 테이블에 기록해둔다. 이를 기반으로 쿼리를 작성하여 테스트해볼 수 있다.
select
max(p.id),
count(pl.product_id) as like_count
from products p
inner join product_likes pl
on p.id = pl.product_id
group by pl.product_id
order by count(pl.product_id) desc
limit 20
offset 0;
좋아요 수를 상품 데이터와 같이 가져오기 위해서는 상품 ID 기준으로 그룹화를 해서 각각 몇개가 있는지를 카운트하고 SELECT할 수 있다.
이러한 쿼리의 실행 결과는 어땠을까? 위에서 정의한 데이터 생성전략을 이용해서 데이터를 입력 스크립트를 실행하고, 해당 쿼리를 DB클라이언트에서 간단하게 실행 해볼 수 있었다.
쿼리를 수행해서 응답을 받기까지 대략 17s으로 상당히 오래걸렸다. 왜 이런일이 발생했는지를 정확히 이해하기 위해 ANALYZE EXPLAIN 명령어로 실행계획을 확인 할 수 있었다. 출력된 결과를 Mermaid로 변환하여 아래에 나타내었다. 실행은 왼쪽에서 오른쪽 방향으로 수행된다. (ANALYZE EXPLAIN을 사용하면 아래 처럼 더 오래걸리는 경우가 있다)
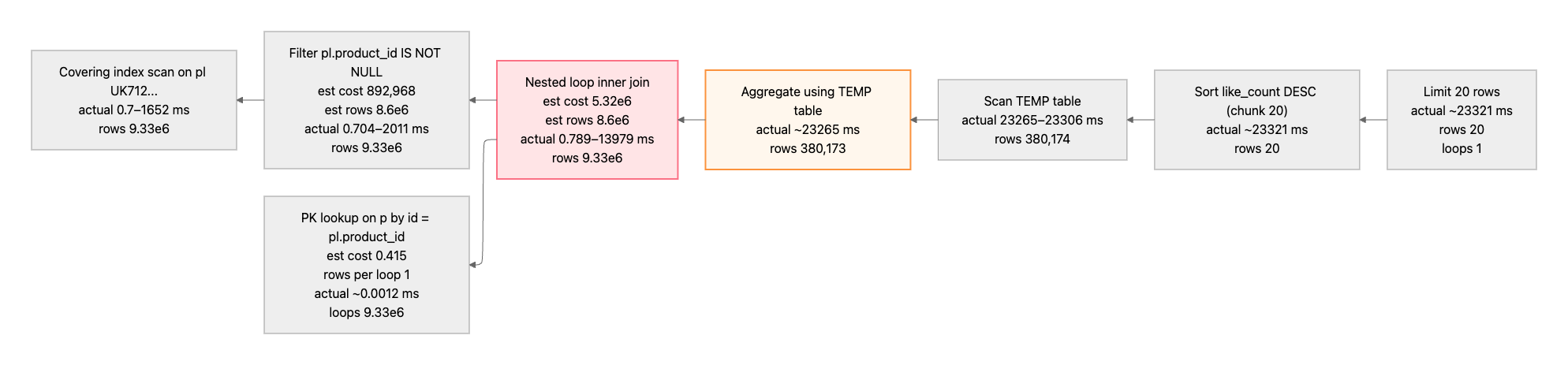
- product_likes에서 커버링 인덱스를 사용하여 990만개의 데이터를 조회한다 (1.6s)
- 여기서 조회된 product_likes 레코드로 product 테이블의 pk 룩업을 하며 중첩 조인한다
- 중첩 조인에서 12s 정도 소요되었다
- 임시 테이블을 생성해서 상품 ID로 집계를 진행하여 38만개의 레코드로 필터링하였다 (9s)
- 임시 테이블을 스캔해서 정렬을 한다
- 오프셋 및 limit으로 SELECT를 해온다
커버링 인덱스를 사용한 이유는 유저-상품의 좋아요수 중복 등록을 막기 위한 unique constraint으로 생성된 유니크 인덱스 때문이다. 좋아요를 조회해서 집계하기 위해 이미 인덱스 내의 필요한 정보(컬럼)들이 존재하기 때문에 물리적인 테이블로 랜덤 I/O 혹은 순차 I/O를 하지 않고 인덱스만 메모리에 올려서 사용할 수 있기 때문에 커버링 인덱스였다.
결과값이 느리게 반환되었던 이유는 결국 상품 ‘좋아요 수’ 기준으로 정렬하려면, 상품-유저 레코드들을 풀스캔 해서 집계해야 한다는 점 때문이었다. 풀스캔을 하여 집계를 하고 정렬을 하기까지 그 순위를 알 수 없었고, 그러한 과정이 결국 읽기 지연으로 나타났다는 결론을 지을 수 있었다.
미리 계산해두면 76배 빨라진다
정규화 섹션에서 발생한 이슈를 해결할 수 있는 방법 중 하나는 미리 계산된 결과값을 테이블에 넣어두는 방식이다. erd를 다시 나타내면 아래와 같으며, 집계를 통해서 계산할 수 있는 중복된 데이터를 넣기 때문에 정규화에서 벗어난 역정규화라고 생각할 수 있다.
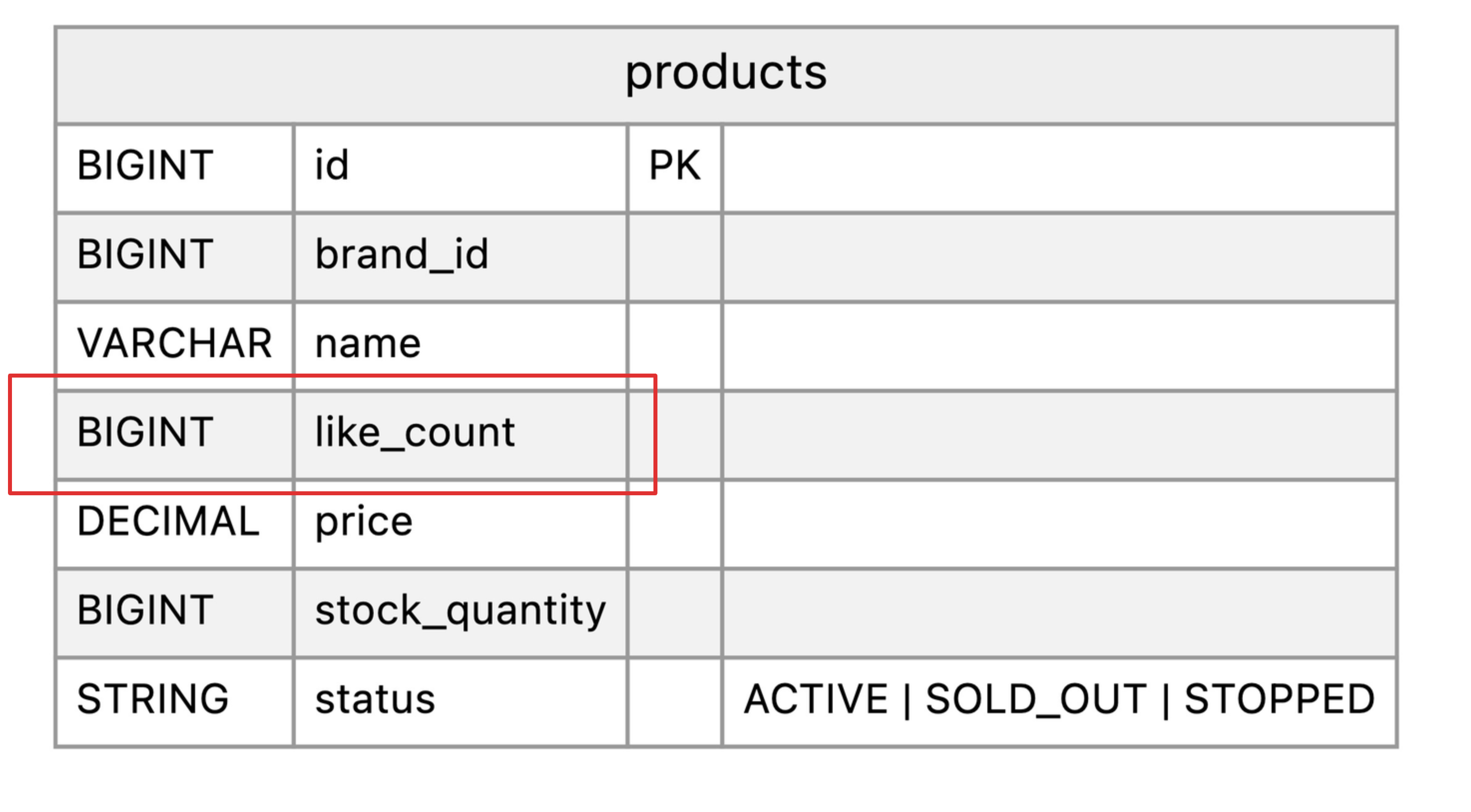
쿼리는 어떻게 작성해야할까? 이미 테이블내에 계산된 결과값을 포함하고 있기 때문에 간소화된 쿼리를 다음과 같이 작성할 수 있다.
select p.id, like_count
from products p
order by p.like_count desc, p.id desc
limit 20
offset 0;
쿼리를 DB 클라이언트에서 실행하고, 실행계획의 결과를 Mermaid를 통해 시각화하였다 :

결과는 17.278 s -> 227ms 으로 조회시간이 98.69 % 감소 (76x 향상) 되었음을 확인할 수 있었다. 실제 프로덕션 환경에서는 결과가 다를 수 있는데 이 테스트 결과는 DB에 독립적인 테스트 결과이기 때문이니 참고해두면 좋겠다.
쿼리 실행계획은 이전에 발생했던 풀스캔 이후의 조인, 임시테이블, 집계과정이 사라졌음을 알 수 있는데 여전히 테이블 스캔을 하고 있었다.여기서도 마찬가지로 테이블 스캔을 하는 이유는 모든 값을 정렬하기 전까지는 페이지네이션을 할 수 없기 때문이다.
역정규화의 목적은 다른 테이블과의 조인 후 임시테이블 생성과 집계과정 제거하는데 있다는 것을 알 수 있었다. 그렇다면 실제로 역정규화를 실무에서 사용하는가? 그리고 효과가 있는가?를 질문해볼 수 있다.
“최근 우리 팀에서 운영하는 서비스의 어드민 페이지에서 컴플레인이 제기되었다”
컴플레인 내용은 특정 페이지의 조회속도가 상당히 느렸고, 같은 고객사 내에서도 계열사에 따라 직원수와 조직도 복잡도에 따라 짧게는 7s에서 길게는 29s의 API응답속도를 보이는 것을 확인하였다.
분명한 원인은 AWS RDS의 Enhanced Monitoring을 통해 확인할 수 있었는데, 대부분의 슬로우 쿼리가 유사한 형태를 띄는것을 알 수 있었다. 조회할때마다 특정 컬럼들을 계산해서 CTE로 임시 테이블을 만들어 조인하는 것이 조회속도를 지체시켰다. 해당 기능은 Procedure로 제공되는 형태였고, 전수조사를 해보니 약 60개의 쿼리에서 사용되며 외부로 약 20개 이상의 API로 연결되어 우리 서비스의 전반적으로 사용되고 있었다.
해결책으로 해당 테이블의 레코드 삽입 혹은 업데이트/삭제 시에 해당 컬럼을 미리 계산해서 넣도록하고, 모든 쿼리를 전수조사해서 제거하는 작업을 한 스프린트 동안 진행하였다. 여기서 질문할 수 있다. 계산이 필요한 데이터를 역정규화해서 넣으면 쓰기 지연이 발생하지 않는지? 이에 대한 대답으로 해당 데이터의 성격에 따라 큰 문제가 없었다.
해당 데이터는 조직 데이터로 인사 시스템 특성상 하나의 조직이 새로 생기거나, 조직 개편 이벤트는 자주 발생하지 않는다. 이 처럼 도메인의 특성을 명확히 이해하고 접근하는것이 설계의 효율성을 이끌어내는데 중요한점인것 같다.
결과적으로 해당 29s 응답속도를 보이던 API는 500ms 이하로 떨어져서 이전보다 앞도적인 응답속도를 보였고, 우리 서비스 전반적으로 발생시키던 DB부하 또한 낮아짐을 Cloudwatch로 확인할 수 있었다.
역정규화 도입할지에 대한 결정은 무엇을 희생(쓰기 지연)하고 무엇을 얻을 지(읽기 성능)에 대한 고민을 도메인 관점에서 접근하면 되지 않을까 싶다.
인덱스를 걸어도 깊은 페이지에서 느려지는 이유
이번에는 상품에 대한 정보를 조합해서 SELECT 절에 조회하는 컬럼들을 추가하였고, 앞에서 본 정규화/역정규화의 예제와 크게 다르지 않다. 쿼리는 아래와 같다.
SELECT
p.id,
p.name,
p.price,
p.stock_quantity,
p.like_count,
b.id AS brand_id,
b.name AS brand_name
FROM products AS p
JOIN brands AS b
ON p.brand_id = b.id
ORDER BY
p.like_count DESC,
p.id DESC
LIMIT 20
offset 120;
이번에는 K6를 로드 제네레이터로 사용하여 측정되는 메트릭을 프로메테우스로 수집하여 그라파나로 관측하였다.
테스트 방식으로 RPS 1로 고정하고 15초 마다 한 페이지씩 넘어가는 쿼리를 보내도록 하였다. 1 RPS를 만족하기 위해 VU 1로도 충분히 커버가 가능함을 확인할 수 있었다.
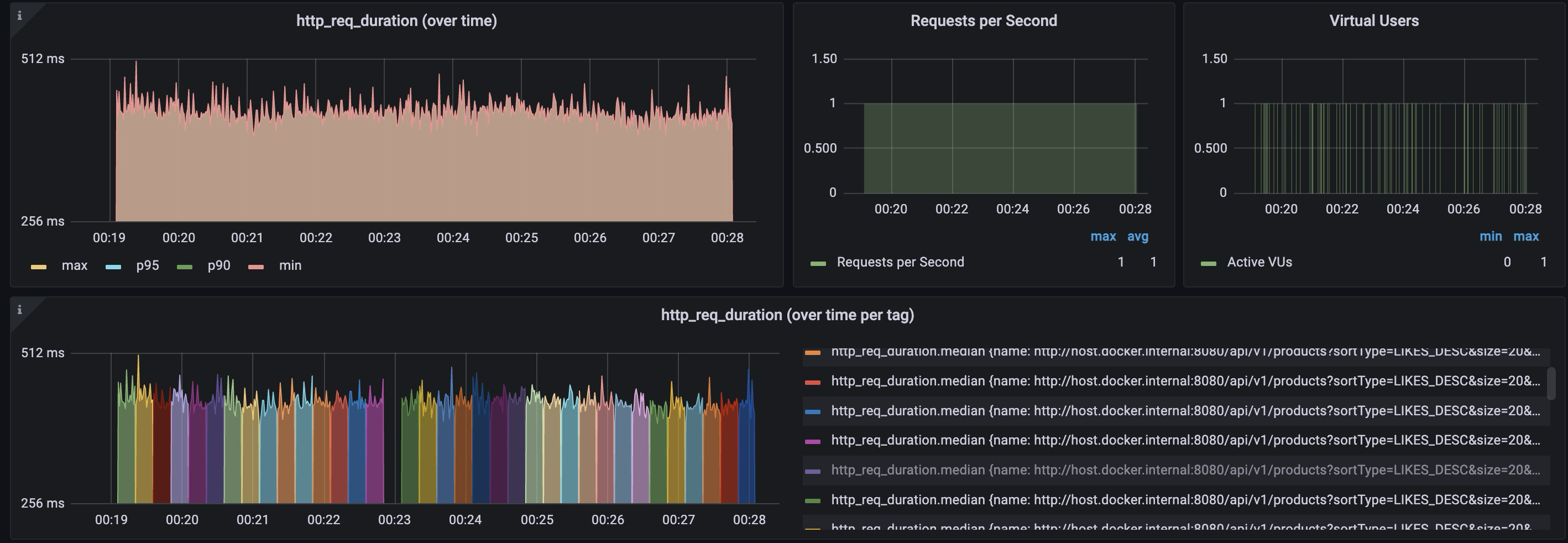
| count | min | median | max | mean | p50 | p90 | p95 | p99 | p99.9 |
|---|---|---|---|---|---|---|---|---|---|
| 539 | 368ms | 406ms | 507ms | 409ms | 406ms | 432ms | 445ms | 464ms | 479ms |
하단 그래프의 컬러 코드가 각각 페이지에 따른 http 요청을 나타낸다. 즉, 각 색깔로 구분된 영역분포 그래프마다 15초를 나타낸다. 이를 통해 페이지 수가 증가함에도 비슷한 http duration값이 유지됨을 알 수 있었다. 그 통계 결과값들을 표에 정리하였다. 가장 오래걸린 값은 507ms이며 데이터의 절반은 406ms 보다 빠르게 응답을 받을 수 있었음을 알 수 있다.
어플리케이션의 성능을 높이기 위해 부하테스트를 통해 병목지점을 찾는 과정이 필요하다 하지만, 여기서는 병목 지점은 DB에 있다는 가정하고 접근하려고 하며 부하테스트 또한 그런 목적으로 진행되지는 않아 관련 인사이트는 얻을 수 없을 것이라고 판단된다.
대신 DB 쿼리에 대한 해석은 실행 계획을 분석하면 알 수 있었다.
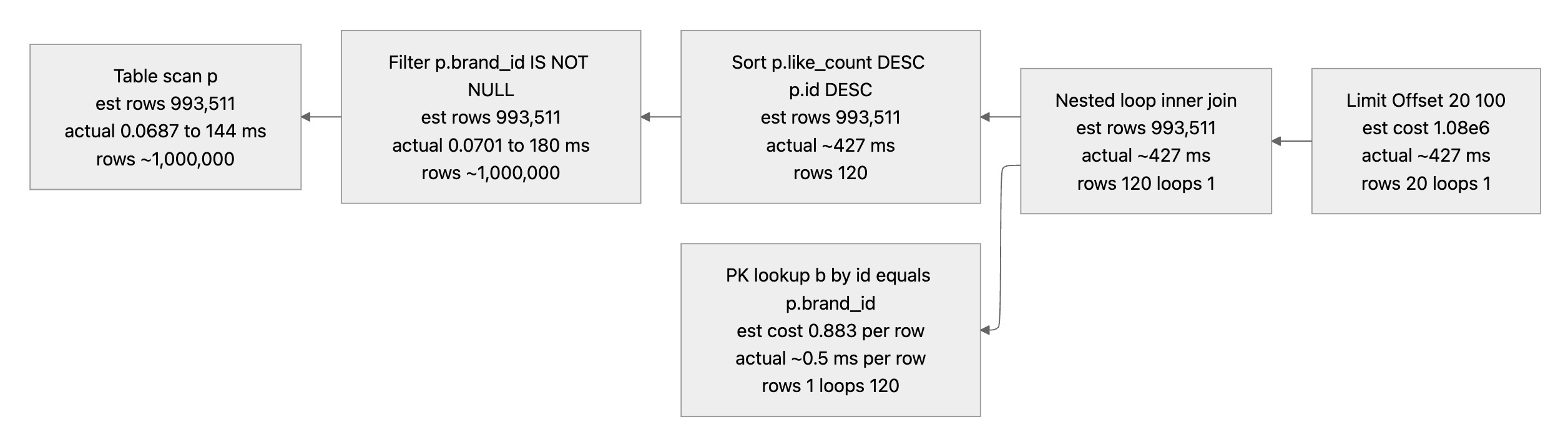
위에서 보여준 실행계획들과 동일하게 좌측에서 우측으로 쿼리가 실행되며 실행과정은 다음과 같이 정리할 수 있다 :
- 상품 테이블의 약 100만개 레코드를 144ms에 걸쳐 테이블 스캔 (동시에 brand id 가 null 이면 필터링)
- 테이블 스캔 및 필터링된 상품 레코드를 좋아요, id 순으로 정렬하며(+240ms) 약 100만개에서 120개를 추려낸다 (120 레코드를 추려내는 이유는 size 20에 offset이 100이기 때문이다)
- 여기서 걸러진 상품 내의 brandId 컬럼을 이용해서 브랜드 테이블의 레코드들을 PK로 랜럼 I/O 해온다 (120 loops)
- 가져온 상품과 브랜드를 Nested For문을 이용해서 조인한다
- 조인된 결과에서 100만큼 offset 하고 남은 20개의 레코드를 반환한다
여기서 100만개의 풀 스캔을 하고, filesort로 정렬을 하는데 400ms 정도의 대부분의 시간을 소요한다는 사실을 알 수 있다. 이 두 가지 시간 소모를 단축시킬 수 있는 방법은 무엇이 있을까?
‘좋아요 수’ 컬럼에 내림차순으로
create index idx_like_count on products(like_count desc, id desc);
analyze table products;
생성된 인덱스를 바탕으로 한 페이지씩 15초마다 증가시키는 API 요청하는 테스트를 진행하면 아래와 같은 결과를 볼 수 있다.
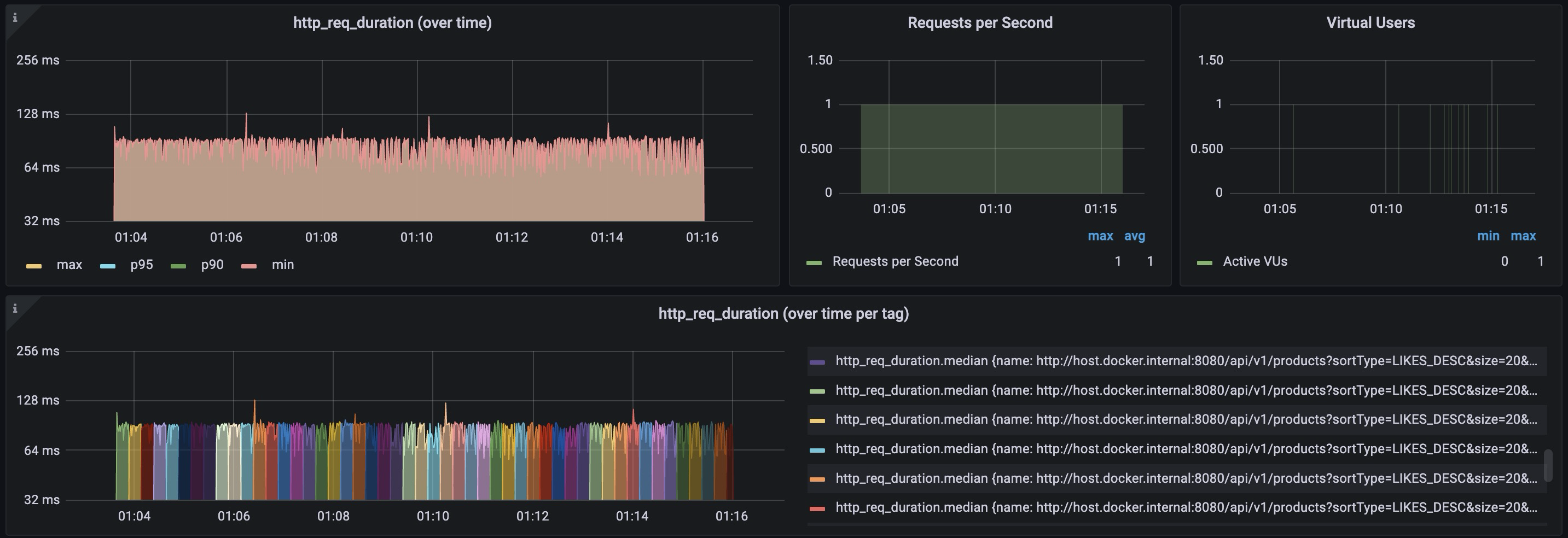
| count | min | median | max | mean | p50 | p90 | p95 | p99 | p99.9 |
|---|---|---|---|---|---|---|---|---|---|
| 743 | 56ms | 89ms | 129ms | 84ms | 89ms | 93ms | 94ms | 97ms | 124ms |
max값을 이용해서 인덱스가 적용되지 않은 결과를 비교했을때, 507ms 에서 129ms로 약 74.5% 단축됨을 확인할 수 있다. 다른 지표들도 월등히 향상된 결과값을 보였다.
그렇다면 인덱스 설정이 실행계획에 어떤 영향을 미쳤을까? 실행 계획을 분석해서 그 까닭을 알 수 있었다.
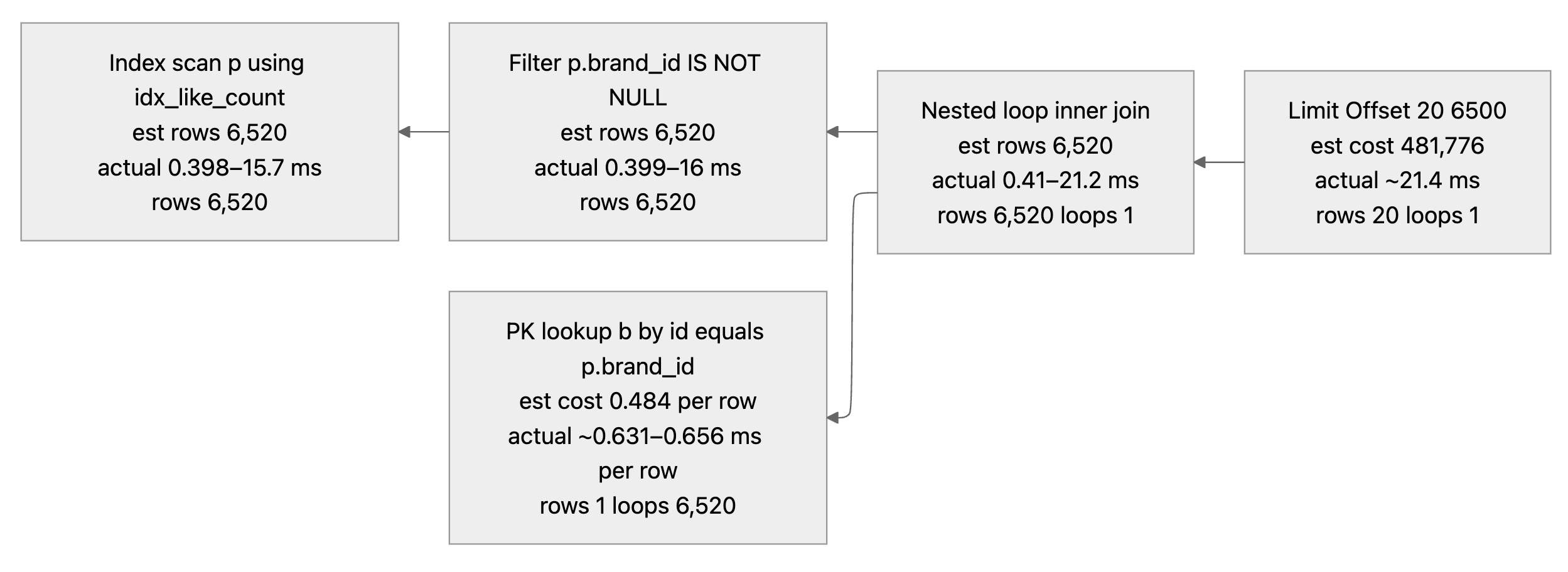
가장 큰 차이점은 인덱스 스캔이었다. 위의 실행과정은 다음과 같이 정리할 수 있다 :
- 인덱스 스캔으로 6520 레코드를 상품 테이블로 부터 조회한다
- 조회된 상품으로 부터 brand_id를 이용해 브랜드 테이블에서 PK 룩업으로 가져와 중첩 조인을 진행한다
- 레코드 20개를 반환한다
인덱스가 적용되지 않았을때는 전체를 가져와 정렬을 진행하는데 많은 시간을 사용했다. 전체를 가져와 정렬을 해야하는 이유는 무엇일까? 여전히 페이징 처리가 적용되어야 하기 때문이다. 전체를 정렬하기 전 까지는 페이징 처리하고자 하는 레코드들의 위치를 알 수 없다.
반면에, 적절한 인덱스가 적용된 경우는 이미 정렬된 데이터구조를 갖고 있기 때문에 이를 가져와서 해당 레코드들의 실제 물리적 위치를 알아내는 방법을 사용할 수 있다. 즉, 전체를 가져와서 정렬하는 시간적인 비용과 메모리 관점의 비용을 줄일 수 있다.
이러한 결과가 항상 반환되는지 확인 해보면 흥미로운 결과가 나온다. 이는 페이지 수가 점점 늘어나면 인덱스를 사용함에도 불구하고 인덱스 스캔을 해야하는 범위가 점점 넓어져야 한다는 사실과 연관되어있다. 처음에는 Offset 방식이면 특정 위치로 점프하여 페이지 크기 만큼 잘라서 가져올 수 없는건가? 하는 의문이 들었다. 예를 들어, 30페이지에 20개를 가져온다면 30페이지 위치로 이동해서 다음 20개만 가져오는 식이다.
점프 하는 방법이 불가능한 이유는 B+트리 구조로 각 노드가 링크로 연결된 링크드 리스트를 기반으로 하기 때문이다. 따라서, 특정 키를 가지고 탐색(seek)을 하는 경우는 logN의 복잡도를 가지지만 N번째 위치 부터 20개를 가져오는 행위를 하기 위해서는 N + 20개의 레코드를 모두 조회하고 N을 버리고 20을 가져와야 한다.
인덱스 스캔도 순차적으로 탐색해서 모두 가져와야한다면 그 비용의 임계점이 분명 존재할것이다. 동일한 테스트로 간단하게 확인할 수 있었다. DB클라이언트를 통해 응답속도가 급격히 느려지는 대략적인 위치를 찾아 동일한 1RPS로 페이지 수를 증가하는 방식의 테스트를 진행했다.
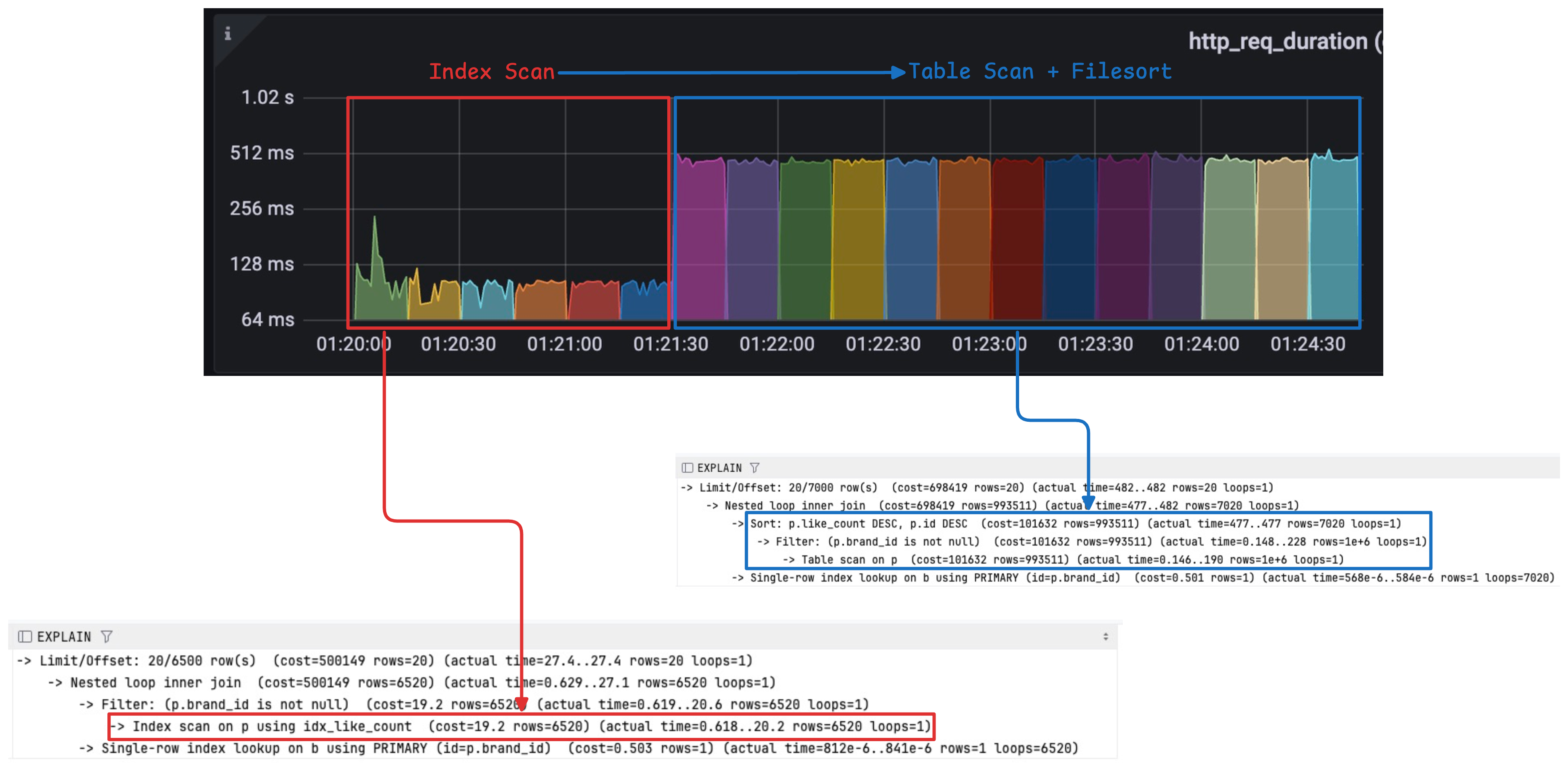
325 페이지에서 시작해서 대략 330페이지인 offset 6600 시점에서 테이블 스캔이 진행되었음을 확인할 수 있었다. 이 결과는 옵티마이저가 특정 시점에서 실행계획이 스위치 처럼 한 번에 전환되는 방식을 따르기 때문이었다.
여기서 의문인점은 왜 전환전까지 응답속도가 일정한가? 였다. 처음 테스트를 진행할때는 페이지 수가 많아질 수록 가져와야할 레코드가 많아져 점진적으로 응답속도가 늦어질것이다고 예상했었다.
내 생각으로는 전환전 응답속도가 일정한 이유로 MySQL 내부 버퍼링 덕분에 캐시 히트율이 높아 동일한 I/O 패턴이 발생하는게 아닐까? 하는 추측을 하고 있다. 이것을 테스트 해보기 위한 방법으로 버퍼풀의 용량을 낮추거나 레코드 하나하나의 용량을 높여서 Disk I/O 및 캐시 미스 발생 확률을 높이는 등의 테스트 방법이 있을것 같다. 여기서는 해당 테스트는 다루지 않으려고 한다.
Offset에서 Keyset으로 전환하면 92.6% 빨라진다
원래 인덱스를 유지하면서 페이지가 깊어짐에 따라 동일한 조회성능을 내는 방법은 무엇이 있을까?
create index idx_like_count on products(like_count desc, id desc);
위에서 내린 결론으로 근본적인 성능하락 원인은 OFFSET을 하기 위해서는 결국 순차적으로 스캔해서 정렬을 할 수 밖에 없는 자료구조를 갖기 때문이었다. 특정 위치로 점프를 할 수 없지만 인덱스 Key가 주어지면 그 위치로 logN 성능으로 찾아갈 수 있다는 점을 이용하면 이 문제를 해결할 수 있다. 즉, 조회 시작 위치를 찾도록(Seek) 쿼리 방식을 바꿔야 한다.
지금까지 비교했던 페이지네이션 전략은 Offset 방식이고, 이와 대비되는 개념은 Keyset 방식이다. Keyset 방식은
마지막 페이지 마지막 행이 (like_count, id) = (?, ?) 였다고 치면,
그 다음 페이지는 이보다 작은(또는 같은데 id가 작은) 값을 조건으로 가져오면 돼.
를 실행하면 된다. 다시말해 특정 조건으로 정렬하여 조회했던 마지막 행의 다음것 부터 가져오도록(seek) 시키면 된다. 이를 SQL 비교 구현한 결과는 다음과 같다. 조회응답속도는 421ms 에서 31ms로 약 92.6%(13.5배) 성능 향상을 보인다. 이 수치는 정말 단순한 비교를 위해서 계산되었으며 실행에 따라 조회응답속도도 달라질 수 있다.
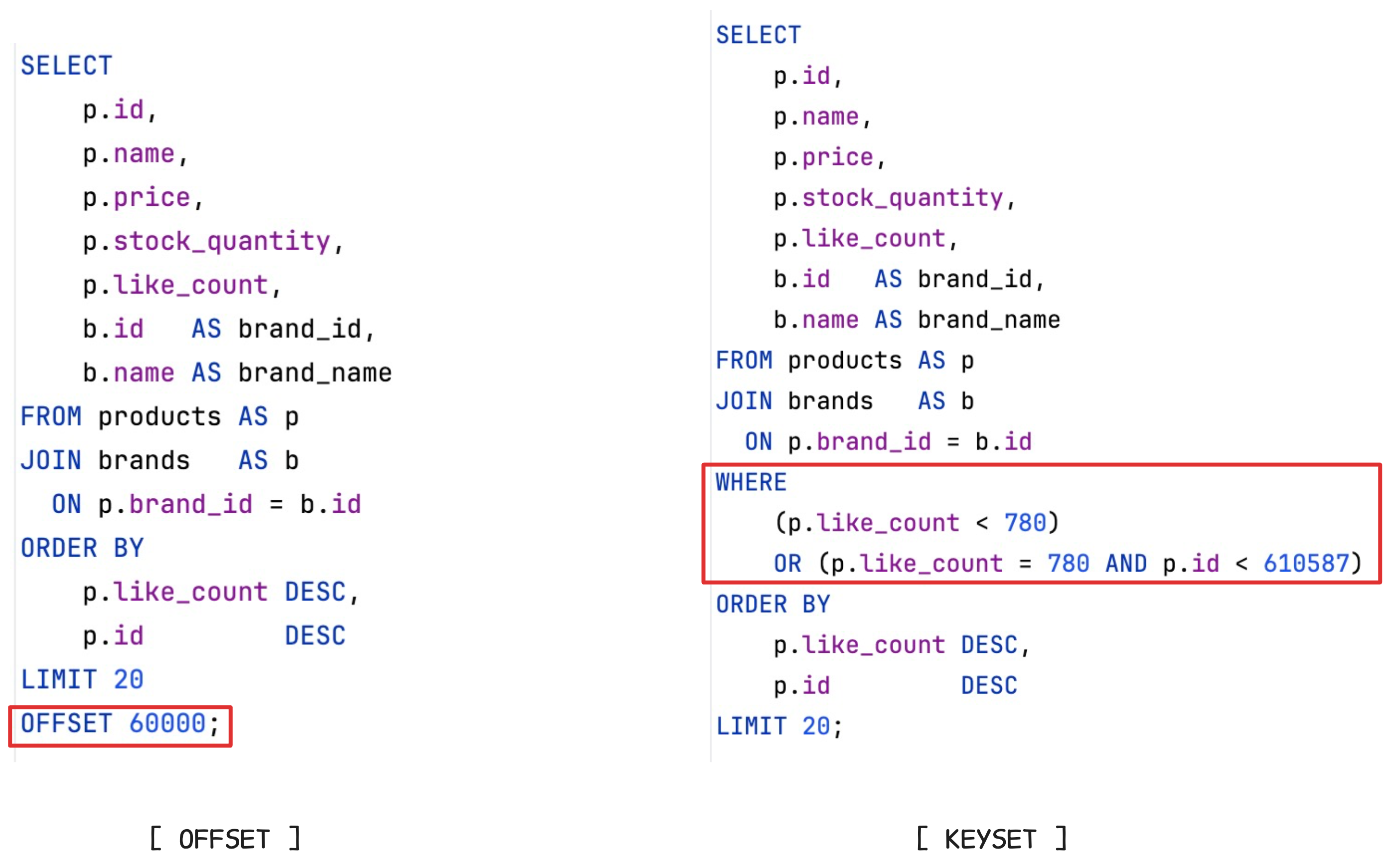
(좋아요, 상품 아이디) 순으로 정렬을 하고 59999번째 아이템의 위치는 좋아요 = 780과 상품 아이디 610587로 seek해서 찾아갈 수 있다. 따라서, 그 다음 아이템에 대한 조건을 위와 같이 걸게 되면 60000번째 부터 20개를 인덱스 레인지 스캔을 통해 가져온다.
실행계획을 분석해도 앞에서 플랜전환되기 전에 보였던 방식인 인덱스 레인지 스캔 방식을 따르는것을 확인할 수 있었다. 그렇다면 두방식의 장단점은 무엇이며 실무에서는 어떤 선택기준을 가질 수 있을까?
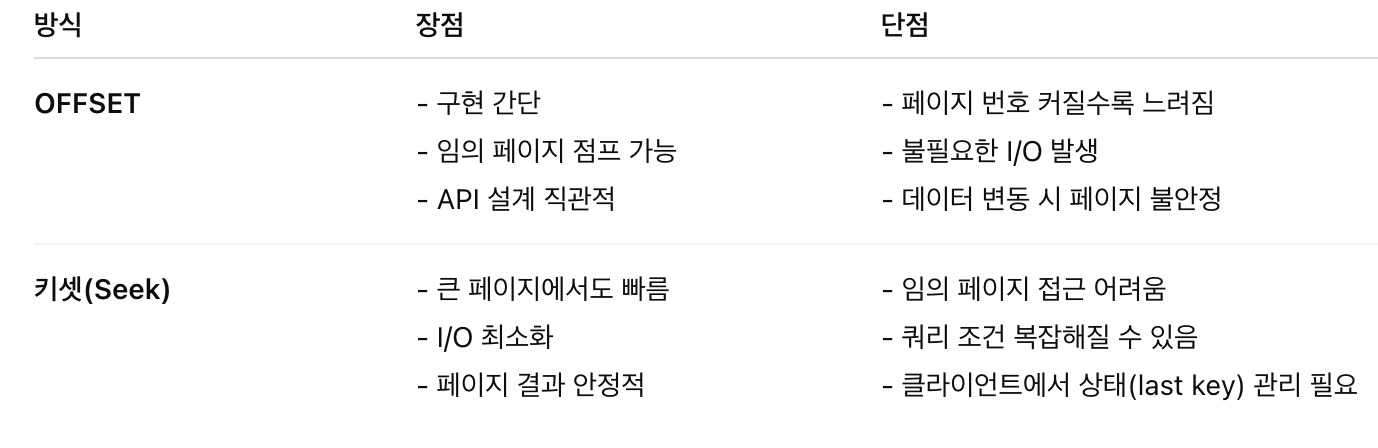
키셋의 가장 큰 단점은 구현이며 오프셋의 가장 큰 장점은 구현이었다.
실제로 실무에서 오프셋을 키셋으로 전환하기 위해 POC를 했는데, 복잡한 정렬조건의 갖는 요구사항 때문에 복잡도가 상당히 높았던것으로 기억한다. 따라서, 단순한 요구사항이지만 피드/스크롤 UI이면서 대규모 데이터 페이지네이션이면 키셋을 선택할 수 있을것 같다. 그럼에도 불구하고 키셋보다는 캐싱과 같은 다른 방식을 좀더 고민해보지 않을까 싶다.
키셋 방식에서 한가지 마지막으로 언급하고 싶은 부분은 구현에 대한 어려움이다.
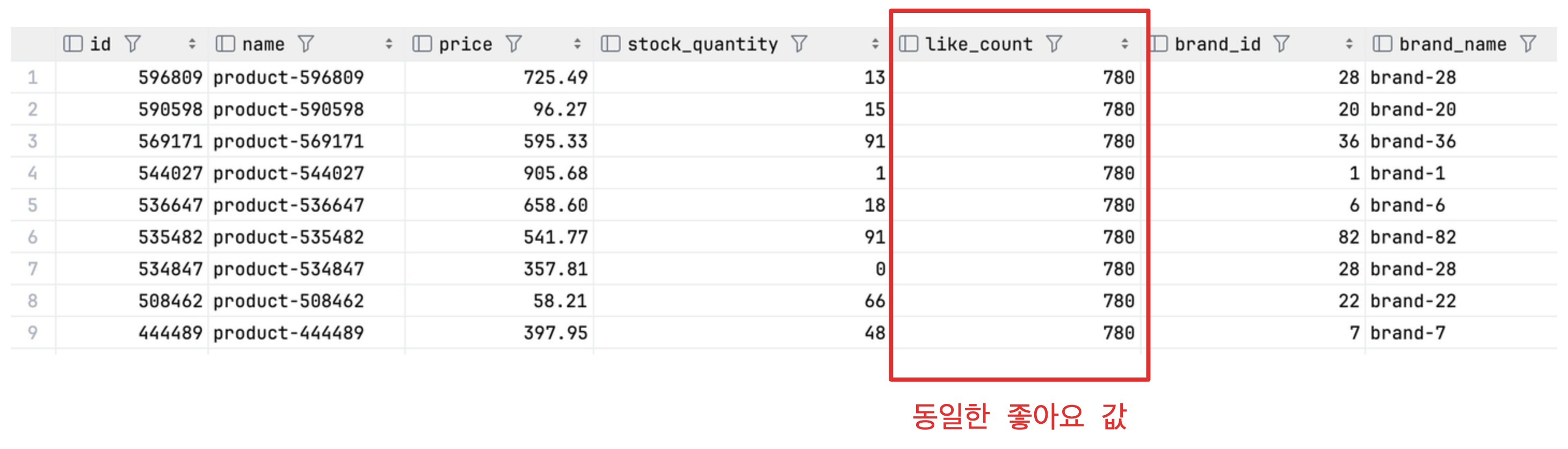
좋아요 수가 780개인 상품은 중복으로 존재한다. 정렬을 고려할때 (like_counts, id)로 걸렸기 때문에 특정 위치를 고유하게 찾을 수 있지만 단순히 아래 처럼 중복을 고려하지 않는 경우 조회된 데이터 결과값이 달라지며 테스트를 해보면 확인할 수 있다.
(p.like_count < 780 AND p.id < 610587)
정렬 조건이 복잡해지면 앞에 조건에는 중복이 발생해도 괜찮지만 마지막은 반드시 유일한 값을 갖는 컬럼을 넣어줘야 한다. 이런 경우에는 아래 처럼 조회 조건에 따라 OR절로 묶어주고 마지막은 id처럼 고유값을 갖는 tie-breaker를 넣어주면 된다 :
참고 : tie는 동점 상황을 얘기하는 경쟁 스포츠 용어인데 말그대로 동점을 구분할 수 있는 요소로 생각할 수 있다
WHERE (p.like_count < :lc)
OR (p.like_count = :lc AND p.updated_at < :ts)
OR (p.like_count = :lc AND p.updated_at = :ts AND p.id < :id)
또한, 클라이언트와 소통을 하기 위해서는 nextCursor라는 오브젝트를 만들어서 아래와 같은 방식으로 사용할 수 있다.
{
"items": [ ... ],
"nextCursor": {
"lc": 780,
"id": 610587,
"brandId": 10,
"sort": "LIKES_DESC",
"exp": 1730000000
}
}
복합 인덱스는 몇 개가 적정한가
원래의 목적인 “브랜드별 상품 목록을 인기순/최신순/최저가순으로 빠르게 제공"으로 돌아가보면 복합 인덱스를 통해 해결해보고자 한다.
인덱스를 설계할때 카디널리티를 고려해야한다. 카디널리티는 데이터가 얼마나 중복되며 얼마나 유일한지를 나타낸다. 가장 간단한 예시는 남녀의 성별은 MALE과 FEMALE로 두 가지이며 (물론 LGBT 등을 고려할 수도 있다) 성별의 카디널리티 또한 2가 된다.
여기에서는 브랜드 아이디로 필터 할때 카디널리티의 영향에 대해 생각해 볼 수 있었다. 입점한 브랜드 자체가 별로 없어서 특정 브랜드로 필터링하는게 의미가 없는 경우가 있을 수 있다. 반대로 카디널리티가 높지만 특정 브랜드에 너무 많은 상품이 쏠려있어 분포가 불균형한 경우도 필터링이 의미가 없을것이라 예상했었다.
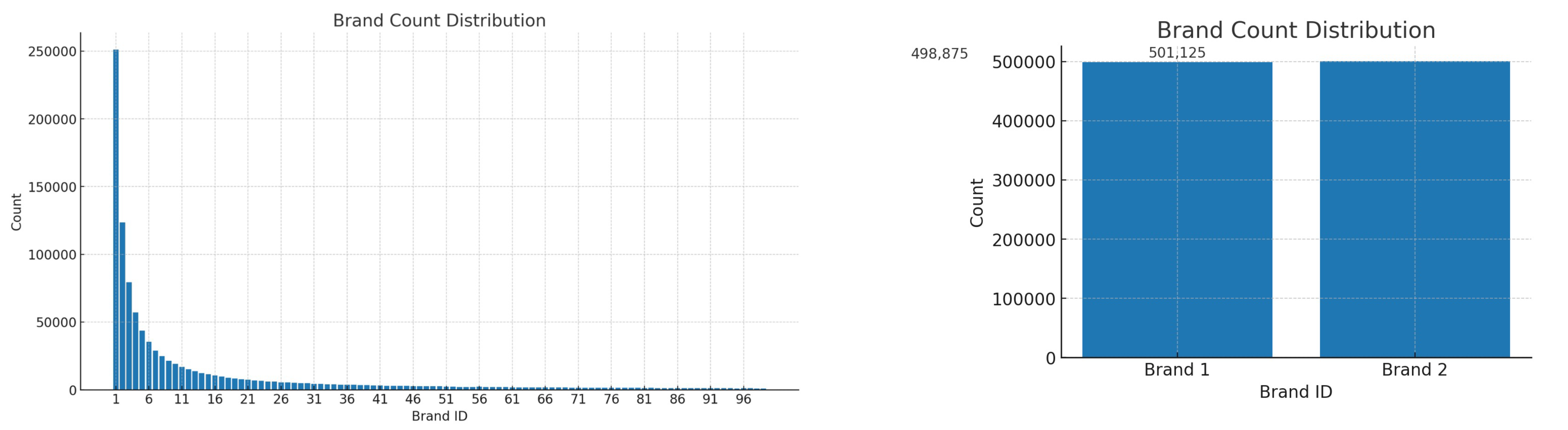
zip’s 분포를 이용해서 왼쪽과 같이 카디널리티가 높지만 상품에 따른 브랜드 아이디의 히스토그램을 그릴 수 있었고, 오른쪽은 균등하지만 카디널리티가 낮은 브랜드 데이터를 생성할 수 있었다.
인덱스 생성은 고려해야할게 많았다. 인덱스를 생성한다는 것 자체가 트레이드오프가 존재하기 때문이다. 인덱스는 쓰기 성능을 손해보면서 읽기 성능을 높여준다. 이 트레이드 오프(인덱스 공간, 쓰기 비용, 버퍼풀 분산) 를 이해하고 적절한 인덱스 설계가 필요하다.
여기서는 그 기준점에 대해서 학습할 수 있었는데 다음과 같다 :
-- 인기순
CREATE INDEX idx_p_brand_likes_desc ON products (brand_id, like_count DESC, id DESC);
-- 최신순
CREATE INDEX idx_p_brand_latest ON products (brand_id, created_at DESC, id DESC);
-- 최저가순 (DESC는 역순 스캔으로 커버 가능하면 하나로)
CREATE INDEX idx_p_brand_price_asc ON products (brand_id, price, id);
기준 : 필터 선두(brand_id) → 정렬키 → tie-breaker(id)
이러한 방식이 보편적인 전략일까? 하는 고민이 들었는데, 앞에서 테스트한 결과를 바탕으로 생각을 정리할 수 있었다.
먼저 where내의 필터를 적용해서 특정 데이터로 seek해서 찾아가야 한다. 물론 카디널리티가 높아야 효과가 크다. seek 후, 특정 조건으로 정렬을 해야하는데 index-ordered scan으로 이미 정렬된 순서를 인덱스 안에 포함하기 때문에 filesort를 제거할 수 있다. 마지막으로 고유한 id값으로 타이브레이커를 하는데, 위에서 언급한 좋아요수 780이 여러 레코드가 있는 경우에도 순서를 결정적으로 보장하는데 사용할 수 있다. 즉, 고유한 값을 마지막에 정렬조건으로 사용하면 동일한 요청에도 항상 동일하게 보장되어 결정된 순서로 조회되게 된다.
여기서 카디널리티와 데이터 분포에 따른 테스트를 진행하고 싶었지만 의외로 인덱스 레인지 스캔으로 두 경우 조회속도가 50ms 이하로 발생하였다. 가정과는 다른 결과가 나와 따로 결과 데이터를 첨부하지 않았다.
그 이유에 대해 고민을 해보면 지금까지 옵티마이저는 비용 최적화된 선택을 해왔다. 카디널리티가 낮아도 full scan 이후의 정렬비용이 너무 크다면 인덱스 스캔을 정렬된 데이터를 랜덤 I/O로 가져오는게 더 나은 선택이라고 판단한것이 아닐까?
실무에서도 고려할 점은 가성비인것 같다. 인덱스 생성 자체가 비용이 있기 때문에 최소한의 비용으로 최대한의 효과를 내야한다. 대부분의 트래픽은 브랜드로 좁히고 3가지 정렬 패턴으로 접근하는데 발생하지 않을까 싶다. 이러한 결정사항은 실제 비즈니스를 운영하면서 통계를 통해 접근해야할 부분이고 테스트를 통해서 판단하는 것과는 결이 다른 내용이라고 생각한다.
여기서 내린 결론은 트레이드 오프에 따른 인덱스를 설정하는 기준점이 있고, 더 나은 선택을 위한 핫 트래픽은 통계적인 분석을 통해 비즈니스 관점에서 접근해야한다는 점이다.
이를 설계된 인덱스를 바탕으로 테스트를 진행하였다. 아래와 같이 0부터 200 RPS까지 15초 마다 10PRS를 상승시키는 RAMPING 방식의 테스트를 진행했으며 그 결과는 다음 그래프로 나타내었다.
| 구분 | 값 |
|---|---|
| Start RPS | 0 |
| End RPS | 200 |
| Step RPS | 10 |
| Step Duration | 15s |
| Hold Duration | 30s |
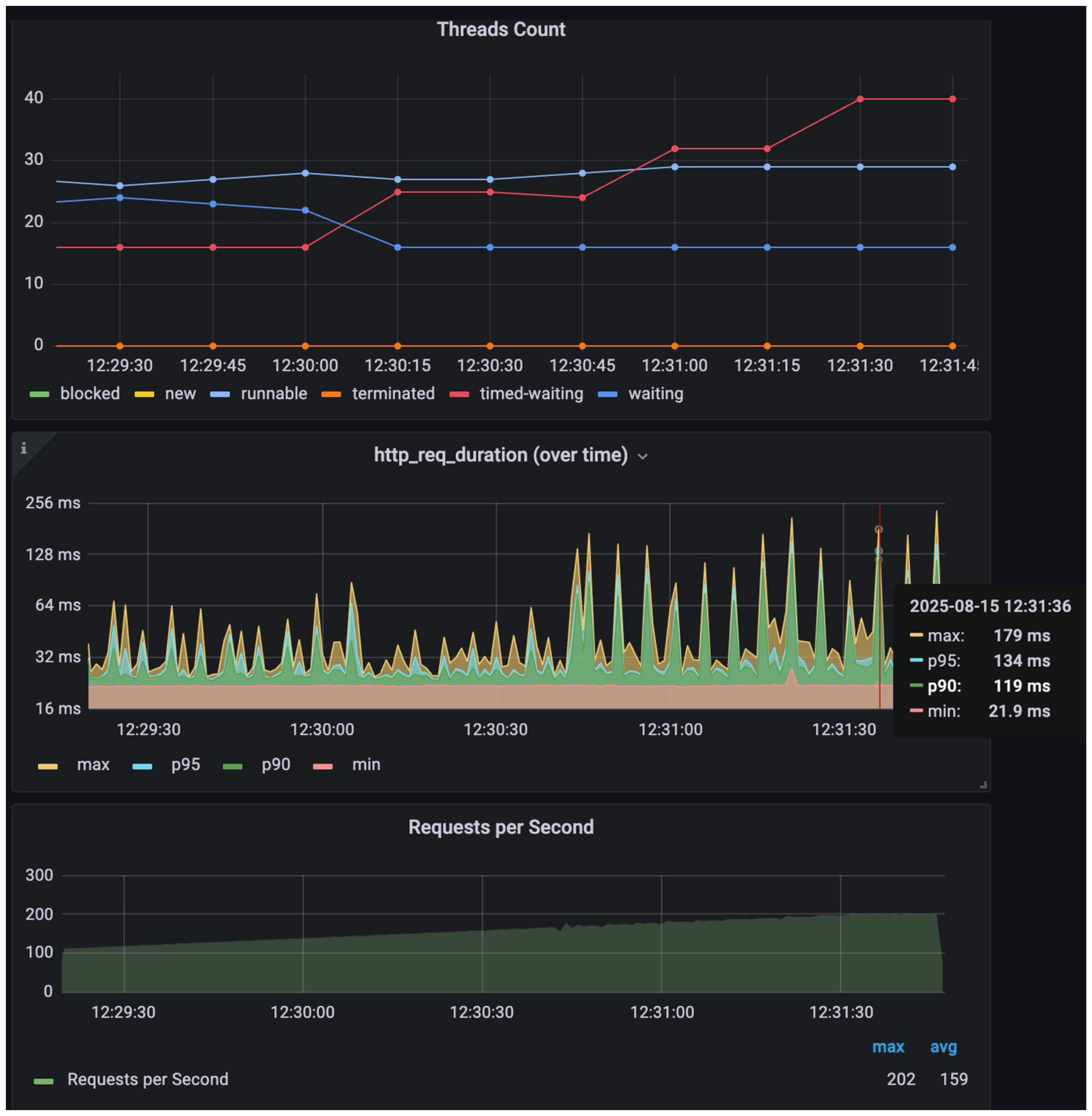
흥미로운 점은 12:30:30 시점부터 p90, p95, max 값이 튀기 시작했는데 이는 k6에 돌려받는 응답속도가 느려지는 요청들이 생기기 시작한다는 점이다. 여기서 제대로 격리된 테스트가 진행되지 않았기 때문에 수치값들은 크게 의미가 없고 추세선을 보는게 중요하다.
병목지점에 대한 인사이트는 JVM내의 스레드 상태에 따른 카운트를 통해 확인할 수 있다. APP이나 DB의 CPU, Memory 메트릭을 확인했으나 이 스레드 상태 카운트가 가장 나은 추세를 보이는 메트릭이었다.
12:30:00 시점부터 timed-waiting 스레드 수가 증가하는 것을 확인할 수 있는데 이는 DB I/O를 하고나서 응답속도가 느려 APP 내 기다리는 스레드 수가 점차 증가하는것을 나타낸다. 너무 많은 요청을 받은 DB는 더 많은 커넥션을 연결할 수 없어 큐잉을 하거나, 너무 많은 요청을 받은 APP이 더 이상 DB와의 커넥션을 연결할 수 없어 APP내에서 큐잉을 하는 둘중 하나일것이다.
해결책으로는 DB I/O 속도를 한자리수의 ms으로 낮추거나 커넥션 풀을 증가시키는 방법일것이다. 이 테스트는 추가로 진행하지 않았다.
캐시를 붙이면 200RPS에서도 ms 단위 응답이 가능하다
캐싱은 조회 성능을 높이기 위한 행위이다.
원본이 저장된 DB보다 물리적 읽기가 빠른 저장소를 활용한 방법으로 구현할 수 있고, 네트워크 관점에서 물리적 위치가 가까운 곳에 위치하여(CDN) 캐싱하는 방법이 있다. 여기서는 레디스라는 In-memory 기반의 key-value store에 저장하는 방식으로 구현을 해보았다.
캐싱 전략에 여러가지 방식이 있는데 빠르게 테스트해보기 위해 고민없이 가장 흔하게 사용되는 Cache-Aside 전략을 사용하였다. Cache-Aside의 동작 방식은 단순하다 :
- 읽기 시도
- 캐시에서 데이터 먼저 찾음
- 있으면 (hit) 그대로 반환
- 없으면 (miss) DB에서 조회, 캐시에 저장 후 반환
- 쓰기 (변경) 시도
- DB에 먼저 쓰기
- 쓰기 성공 후 캐시 데이터를 삭제 (Invalidate)
- 다음 읽기 요청시 최신 DB값이 캐시에 채워짐
이를 구현해서 상품 목록 조회하는 퍼사드 객체 내 메서드에서 캐싱처리하게 하였다. 너무 구체적인건 LLM이 있어서 더 이상 의미가 없어보이고 전략이나 진행 중 고민 포인트들이 여기서 공유되는게 더 중요할것 같다.
결과를 확인해보고 싶어, 앞선 테스트에서 통계값이 튀던 200RPS로 빠르게 도달하도록 부하테스트를 진행했다.
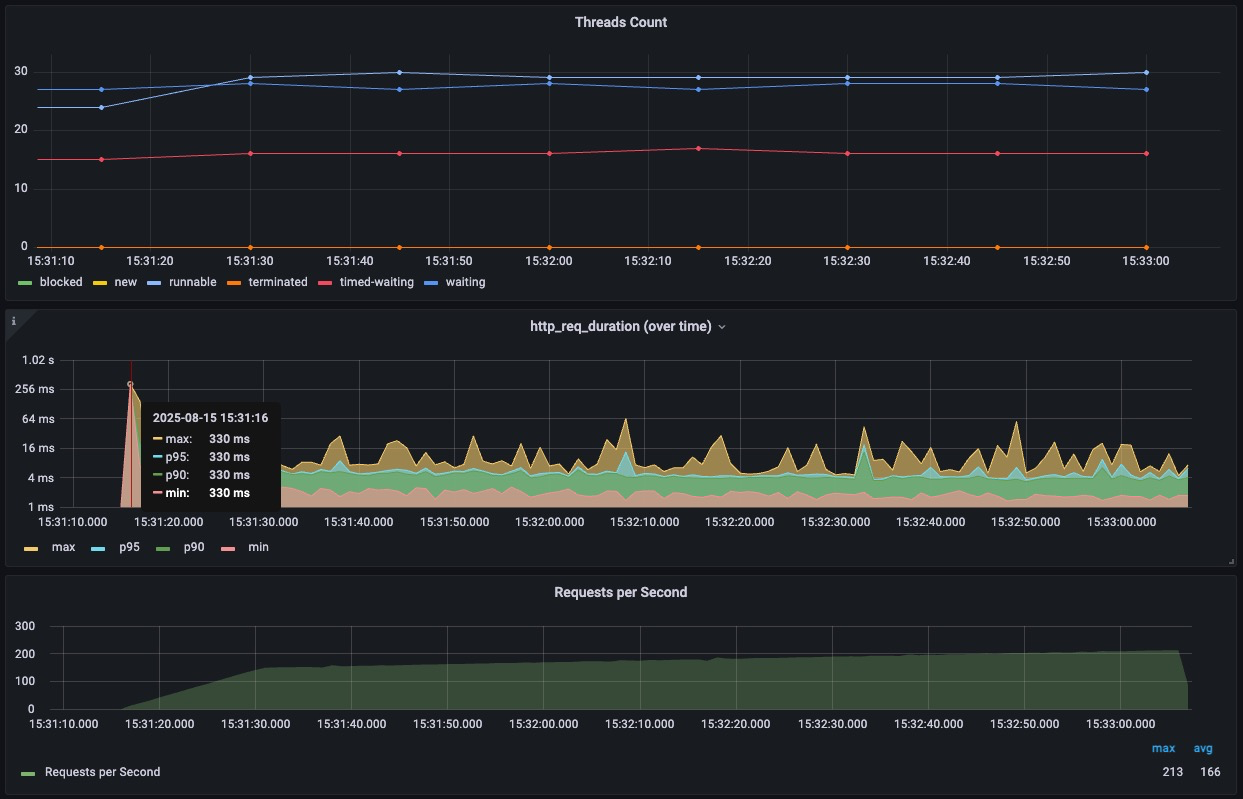
| count | min | median | max | mean | p50 | p90 | p95 | p99 | p99.9 |
|---|---|---|---|---|---|---|---|---|---|
| 18635 | 1ms | 3ms | 330ms | 4ms | 3ms | 5ms | 6ms | 11ms | 46ms |
앞선 테스트와 비교했을 때, 스레드 상태변화가 거의 없었다. DB에서 조회한 결과값들을 레디스에 저장하고 APP 내의 스레드들은 요청이 들어왔을때 단순히 서빙하는 용도로만 사용되고 있었다.
아마도 요청이 더욱 많아지면 톰캣 스레드에 큐잉이 생겨서 지연이 될것으로 예상되는데 그때는 단순히 서빙을 위한 서버들을 스케일 아웃하는 방식으로 해결을 할것 같고, 레디스의 읽기 지연이 발생해서 병목이 되면 레디스로 레플리카를 두는 방식으로 스케일 아웃을 하게될것 같다.
여기서 적용한 Cache-aside 전략 외에도 Read-Through, Write-Through, Write-Behind(Write Back) 등이 있다. 캐시가 읽기 성능이 확실히 좋다는건 결론은 내릴 수 있지만, 이 정도의 피상적인 지식으로는 함부로 적용해서는 안된다는 판단이 내려졌다.
어떤 포인트들을 고민하면 좋을지 GPT에게 질문을 했고, 일부 항목들은 멘토님이 공유해주셨던 내용들도 포함된다.

여기서 TTL, Evict Policy와 같이 언제 캐시데이터를 제거하고 로딩하는지를 가장 먼저 고민해야할것 같다. 캐싱은 원본 데이터와 다르기 때문에 서비스에 따라 실시간성관점에서 어떤 요구사항이 필요한지를 먼저 검토해야할것 같다.
회사에서 일부 개발 중인 서비스 내에서 권한을 레디스에 넣어서 관리하는 팀을 본것 같은데, 권한처럼 데이터의 실시간성이 중요한 경우는 좀더 고려가 필요한게 아닐까 하는 생각이 문득 들었다.
상품 목록을 캐싱 처리하는 경우는 브랜드가 입점해서 순위에 민감한 경우 TTL을 그리 길게 잡을 수 없을것 같다. 하지만 짧은 시간 동안 캐싱처리 된다해도 의미가 없는건 아니였다. 그 짧은 시간에 수만건의 RPS를 1번의 DB 조회처리로 가능하다면 짧은 TTL도 의미가 있다고 생각한다. 캐시 관련된 내용은 이렇다할 결론을 내릴만큼 경험이 많지않고 학습이 부족한 상태인것을 깨달았다.
한 주내에 인덱스와 캐싱 처리를 모두 학습하기에는 짧은것 같고 시간을 더 내서 학습하며, 실무에서 어떤 포인트에 적용하면 좋을지에 대한 고민을 계속해야겠다.
참고한 자료
- Optimizing SQL Pagination in MySQL | readyset
- Zipf’s Law | Wiki