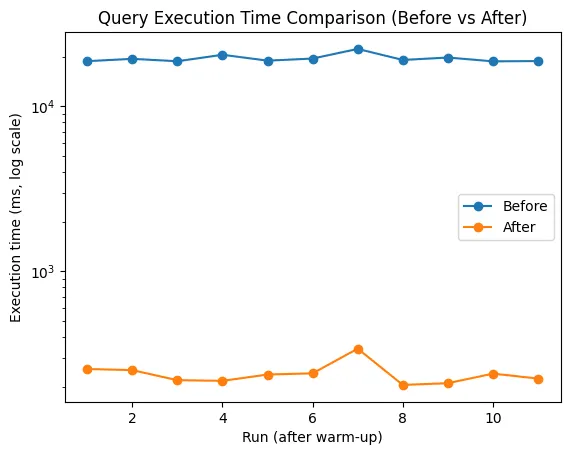
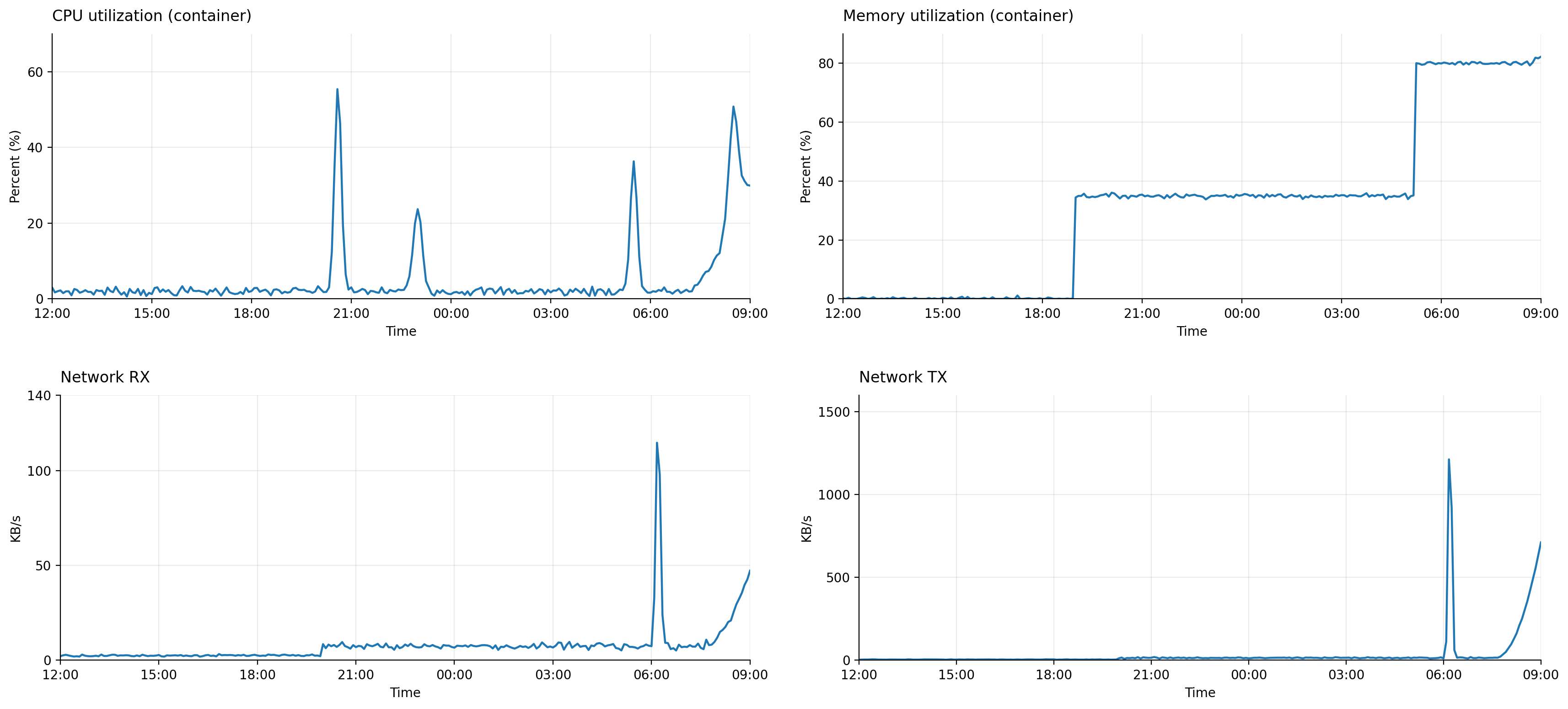
문제 현상: 8개 Fargate Task 중 1개만 메모리 사용률이 지속 상승 (60% → 97%) 결과: 메모리 알람 후 해당 Task 재시작 특이점: 동일 코드 기반의 다른 Task들은 GC 정상 작동 환경: Java 21, Spring Boot, Kafka Consumer, MyBatis Batch, AWS Fargate 증상 분석 CloudWatch 메모리 그래프: 특정 Task만 계단식 상승 덤프 서버: 동일 이벤트 처리에도 톱니형 GC 패턴 (정상) GC 자체 문제라기보다는 객체 참조 유지로 인한 회수 불가 상황에 가까움 원인 분석 대량 청크 메시지 권한 갱신 이벤트를 한 번에 2,500건 단위로 Kafka에 게시 특정 Task가 해당 청크를 독점 처리하면 순간적으로 수만 개 객체 생성 중복 역직렬화 Consumer 내부에서 Map → DTO → VO 변환을 최대 세 번 반복 일시적 객체 폭증, Eden → Old Gen 승격 가속 MyBatis Batch 누적 ExecutorType.BATCH 사용 시 flushStatements() 전까지 파라미터 참조 유지 GC 입장에서는 여전히 “사용 중” 객체로 인식 컨슈머 병렬성 부족 단일 스레드 리스너로 동작 특정 파티션이 한 Task에 몰리면 부하 편향 및 메모리 사용량 집중 GC 관점에서 정리 구분 설명 GC는 참조가 끊긴 객체만 수거 리스트, 세션 등에서 참조 중이면 회수 불가 부하가 높으면 safepoint 진입 지연 GC 실행 타이밍이 밀리면서 Old Gen 누적 Old Gen 승격 가속 장수 객체가 많아질수록 Old Gen 압박 증가 덤프 서버에서 정상인 이유 부하가 낮아 GC 개입 여유가 충분 단기 개선 해결책 조치 설명 기대 효과 DTO 직접 바인딩 @KafkaListener에서 Map 대신 DTO로 수신 중복 역직렬화 제거 청크 분할 처리 2,500건 → 500건 단위로 분할 처리 동시 생성 객체 수 감소, 생존 시간 단축 리스트 참조 해제 처리 후 리스트 clear() 또는 참조 null GC 회수 가능 시점 앞당김 Batch flush 주기 조정 200건마다 flushStatements() 호출 MyBatis 내부 파라미터 참조 조기 해제 필드 누락 복구 누락된 accessType 필드 복원 불필요한 대량 delete 방지 장기 개선 해결책 Kafka Consumer 병렬성 향상 (factory.setConcurrency(2) 등) Partition assignment 전략을 cooperative-sticky로 조정 DLQ(Dead Letter Topic) 구성으로 재시도 루프 제거 Micrometer로 배치 크기, 처리 시간, lag 메트릭 수집 및 모니터링